

User Comments on: "How can a Data Scientist refactor Jupyter notebooks towards production-quality code?"
User Comments on: "How can a Data Scientist refactor Jupyter notebooks towards production-quality code?"
2022-06-12

[Edit]
Join our Discord community, “Code Quality for Data Science (CQ4DS)”, to learn more about the topic: https://discord.gg/8uUZNMCad2. All DSes are welcome regardless of skill level!
See also: https://laszlo.substack.com/p/refactoring-the-titanic
[Edit]
I got a couple of questions from a reader for this article [link], and I thought I share my answers in a blog post:
Hello, Laszlo. Thank you for the material, I have a couple of questions.
Comments are always welcome. I try to answer all of them as this is the best way to explain exactly what is most relevant.
What exactly compared to what?
It’s this image that the questions are about:
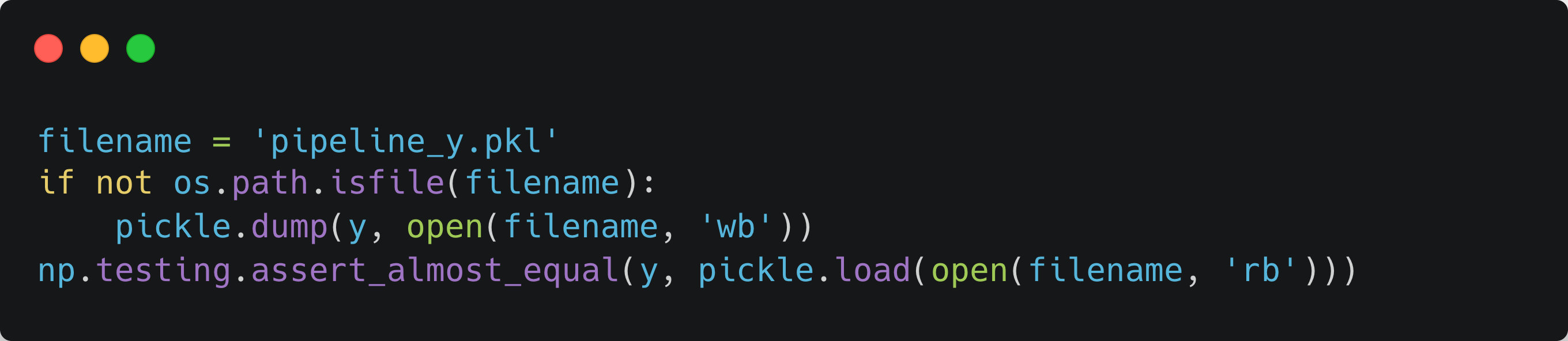
1. What exactly do you assert, comparing "y" with the optimal model results pkl file? Model can produce metrics, feature importances, predicted values, etc. What should I consider?
Anything you want to make sure that needs to stay the same if you refactor (which means changing the code without changing its behaviour). This also needs to be deterministic and computationally stable. If it is not, pick a different value or even make a processing step on it before caching and comparison.
2. In your assertion code "y" stands for predicted labels, I assume. So it returns false if one of predicted labels is not equal to the one from the ideal-model (pkl file). But how can it help in testing? I won't even know which value is wrong and, especially, why is it so.
I am not comparing the predicted labels to the ground truth but to a previous run of the same code, a very important difference. Refactoring aims to make your code more flexible and easier to read, not to improve model performance. Why do you do it anyway? Because it is easier to make model improvements on clean and refactored code.
I still can't see the usability of the assert_almost_equal() method. This may be a very basic approach, just to know that some results are different. But I suppose, there should be a more sophisticated, quantitative implementation of the comparison (e.g. I have ROCAUC and F1 scores in my pkl file and I can compare how much my new results are different from the baseline).
This is purely to see that between two changes of the code, the output didn't change. Just like when you rerun unit tests. How do you know it still does what it did before? Because the tests are passing, they create the same output as compared in assertions.
If you change your code to improve the behaviour, you expect these tests to fail. So given which one is expected to fail you can verify that you changed your code just like you wanted and the improvement (or deterioration) was the result of your last change.
Let's say you want to improve results by changing a processing function in post-processing. Suddenly a test comparing inputs after pre-processing fails. That is definitely strange and not as intended. Now you need to investigate what's the reason. (For example, your pre- and post-processing are coupled through some functions).
But if you verify that only the right tests failed and the overall performance improved, then you can delete the relevant cached pkl-s and rerun your code (without any changes). This will recreate your reference files to compare against, and now you are in a stable state again.
And the cycle continues.
Naming things
3. You have get_names methods in your TestNameLoader and SQLNameLoader classes. I am pretty sure, it breaks one of the OOP principles.
The whole point of interface programming is that the "Process" class doesn't know which is plugged in. It just knows that it has a "get_names" function that will give it "names" objects. So it is not an error. They must have the same name.
4. Same for the Process's run() and the Typer's run() methods.
This is not mandatory as the two classes have different roles. They are not implementing the same interface. You can argue that it is sloppy to name them the same, but I think it is pretty descriptive of what they do: "They run the main body of each class".
5. I don't see the purpose of the TestNameLoader class. It only saves the dataset into a pickle file and returns 0-sample_count rows from it. Shouldn't you name it "Dataset_file_loader" instead?
The point of TestNameLoader is that you can get names from a file and don't need to go to the database (unless you don't want to). The point of refactoring is to run the refactored code continuously at every minor change. This needs that the main part of the code runs fast. This is impossible if you need to connect to a database each time. So you need to create an alternative source. It also has the additional benefit that the main part of your code will not be dependent on where the data is coming from. This is a desirable property called "decoupling".
Yes, I can see that. Isn't just the class's name misleading? This class deals with files, not with testing, ain't it?
Yes, I can name it "MockNameLoader" or "FileNameLoader" these are indeed probably better names. (Which can be easily done if you set this up as renaming is trivial in this framework.
Thanks for the questions
Great questions. Thanks for your feedback. The best way to explain these concepts is through reader questions. Unfortunately, I get very few, so I celebrate each one.
It's probably horses for courses but I don't like tests that fail just because I've *changed* something. I prefer them to fail when I *break* something. This leads to less cognitive overhead and is much more useful (I know when I changed something because I just executed `git push`).
Also, pickling objects and comparing them can make the test suite very fragile. For example, a schema change will break the tests even if nothing is actually wrong.
I've found a better strategy is to make vague but accurate assertions. For example, I don't know exactly how many p-values are going to be less than 0.01 for a linear regression model on randomly generated, synthetic data but I expect it be most of them (depending how much bias I've added to the test data).
Interesting stuff. ML has a lot to learn from SWE and this fascinates me.