
Cloud, Data, AI, GenAI
2024-01-03

Let's start 2024 with a quick thought piece: AI and GenAI are consistently mixed in the public discourse, although they have little to do with each other. And we didn't even speak about the data that fuels them. So here is a short clarification:
What's the difference between cloud computing, data stacks, (traditional) AI and generative AI?
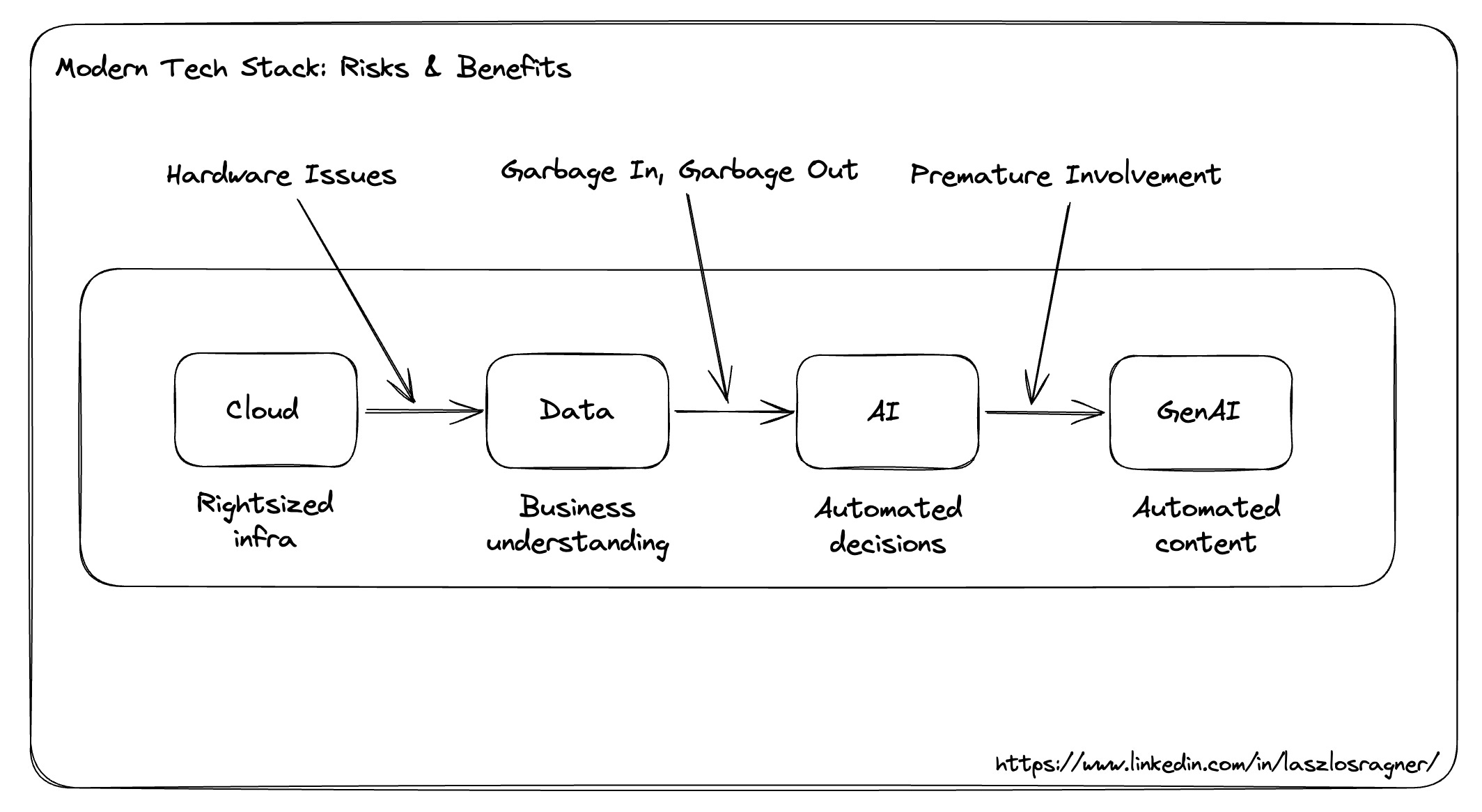
Let's start with the basics: cloud computing
As someone jokingly said. "Cloud computing is just someone else's computer". This is true, but the main benefit is the flexibility of using resources and the enablement of experimenting with new techniques without high upfront hardware costs. If you ever want to get into a business-specific GenAI without speculatively spending a lot of money on GPUs, you need to sort out your cloud migration first.
In 2024, this is mainly an engineering problem with a long list of SaaS providers, contractors, and consultants at various abstraction levels.
Next, the table stakes: the data stack
The Modern Data Stack got much flak recently but achieved one thing: Simplification. All organisations have a clear playbook on how to get the basics right and not struggle with collecting and managing data. How (if) you use the information extracted from this for business-relevant purposes is a different question, but that's not going to be the fault of the databases. Again, providers and consultants will sort this out if there is an organisational will.
You _must_ get this right before you can move on to AI/GenAI. But again, there is a playbook, and you can optimise/tailor that later. Otherwise: Garbage In, Garbage Out.
Moving on: (traditional) AI
This is where things get muddier. ChatGPT takes millions of dollars to train, and Google releases a model whose parameter number can only expressed in exponential form. Yet, your competition with three data scientists claims they are "doing AI".
(Traditional) AI (formerly known as Machine Learning and even formerly known as Statistical Analysis) is a set of well-defined tools that can extract business-relevant information from large amounts of data.
Easy access to data and data quality is paramount, so the first two points above must be resolved first.
You will hear terms like "Logistic Regression", "Random Forests", and "Feature Engineering". These are relatively cheap (compared to GenAI) techniques that have a proven history of working for structured data (the majority of data most companies collect).
The resulting models can be used in decision support or directly in your business processes (either internally or externally by your users). MLOps is a set of techniques to productionise and professionalise these models and is a must-have for any serious application. It is less of a playbook than Modern Data Stack but neither the Wild West of generative AI.
The last frontier: GenAI
2023 was the year of generating content with machines. This excited everyone, and the resulting hype cycle made every CEO have the mother of all FOMOs. This led to endless POCs, "Talk to your documents", and "Talk to your data" initiatives.
But let's clarify a couple of things here anyway:
There are two main approaches in the space: Prompt engineering and Finetuning. (The third, namely, building large models from scratch, is irrelevant for 99% of companies).
Prompt engineering:
You carefully form a piece of text (the prompt), expecting an existing model to answer correctly. You use a third-party provider (e.g. OpenAI) or self-host an open-source model (Llama 2 from FB, but you better have a kick-ass cloud infra, as I wrote in the first point). But we are talking about a one-size-fits-all service.
Any information specific to your company must be sent in that prompt, and you hope that the machine will have enough common sense to interpret that and your request so that its answer makes sense. Otherwise -> hallucinations.
One relevant keyword here is RAG: Retrieval-augmented generation. This just means that while forming the prompt text, various techniques that plug in business-relevant information, hoping that it will improve the answer.
You asked the machine about forecasts for Q2? Drop in every report in the company from Q3-Q1, just in case.
This is probably the most straightforward task on the list from an engineering perspective. But that can be deceiving because now 100% of the problems are business problems, which requires all initiatives to have a well-defined and meaningful business goal and benefit. Otherwise, see "Talk to your documents" with questionable outcomes.
Finetuning:
This is a continuation of prompt engineering by other means. Essentially, a business-specific filter is put on top of an existing large (open-source) model. This short sentence opens an entire set of cans of worms. To achieve this, you need:
Well-operating cloud infrastructure to run the process on. (See above.)
A set of tools (aka "LLMOps") to orchestrate the process (Which are in infancy compared to the Modern Data Stack and MLOps.)
Available GPUs (Which you need to acquire in a hot market; everyone wants to finetune.)
Existing fine-tunable open-source models. (It's unclear ATM how and on what data these were trained and any objective performance metrics)
Data to finetune the model (See point two above and RAG, but if you get those right, this should be straightforward)
Relevant business problem (If you are already doing the PE and RAG, hopefully this is well defined)
Evaluation criterion (This should be obvious, but apparently not. Does this whole thing make sense? What's the benefit? Look at this list. You need to get all of these right. You better be sure it is worth it.)
As you can see, finetuning is somewhat experimental right now, but it will undoubtedly mature eventually.
As always, diligent work progressing forward on the stack will future-proof your tech org, so you will be ready with the capability when a business-relevant opportunity arises.
In 2024, I plan to go back to my original topic of “business relevant AI”, so subscribe if you want more content on this:
clearly explained, thanks!