

[Edit]
Join our Discord community, “Code Quality for Data Science (CQ4DS)”, to learn more about the topic: https://discord.gg/8uUZNMCad2. All DSes are welcome regardless of skill level!
[Edit]
I recently worked on a major greenfield modelling project in the financial sector. I had a tight deadline and no constraints on how to achieve my goal, but the task involved a large amount of “data logistics”: Moving stuff around and representing complex domain knowledge in code.
My workflow is usually pretty simple:
Write all code in classes (as proto-services)
Plug them together and instantiate the classes in a notebook
Load the data into the notebook and feed it to the “service”
Record state and output and visualise with plotly (I should write a post on that as well)
As I was progressing with my code, I had to create numerous entities, each with their own properties, and then use these entities to do the “logistics”: mappings, sortings, searching. Then at the visualisation state, extract data from these entities and print them in a sensible format.
While we are big on data modelling, this time, because of the tight deadline, I thought to cut corners and use dictionaries for storage and turn the relevant parts of these into a single string to be used as keys in other dictionaries. Of course, this became unmanageable. Some classes were complex enough that I used python classes for them from the get-go, but then I needed to write hash, order, repr and many other functions.
While browsing the internet, I bumped into this video: [YouTube] that looked promising to give a try. Especially the parameters to the decorator but more on that later. My progress slowed down anyway because of the tech debt, so a larger refactoring was due (so much about cutting corners to be faster).
Dataclasses
Dataclasses are primarily syntactic sugar to create classes that are somewhere between a named tuple and a “real” python class. They are often created to be immutable (which is generally a good idea), but this is not enforced by default.

You just use the decorator and list the class’s properties with their type. You immediately get __repr__() and __str__() printing facilities out of the box:
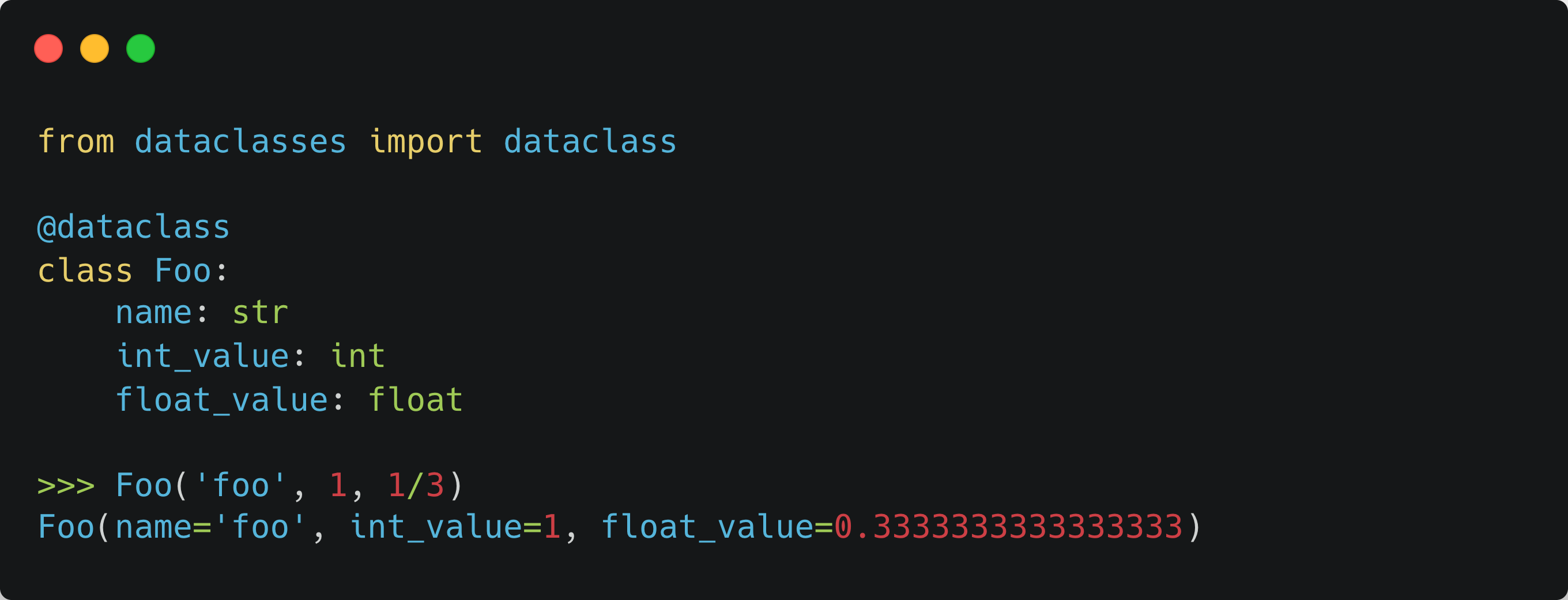
If you would like to use the class as a key in a dictionary (instead of some hack I mentioned above like extracting IDs from classes and using them as keys), turn the class into “frozen”. This will auto-define the required __hash__() function.

If you would also like to order these classes, use the “order” parameter (you can do it independently from “frozen”):

Next step is to store these and reload them from records. We will need the provided “asdict” function for this (see also how to use gzip and jsonl-s for storage):
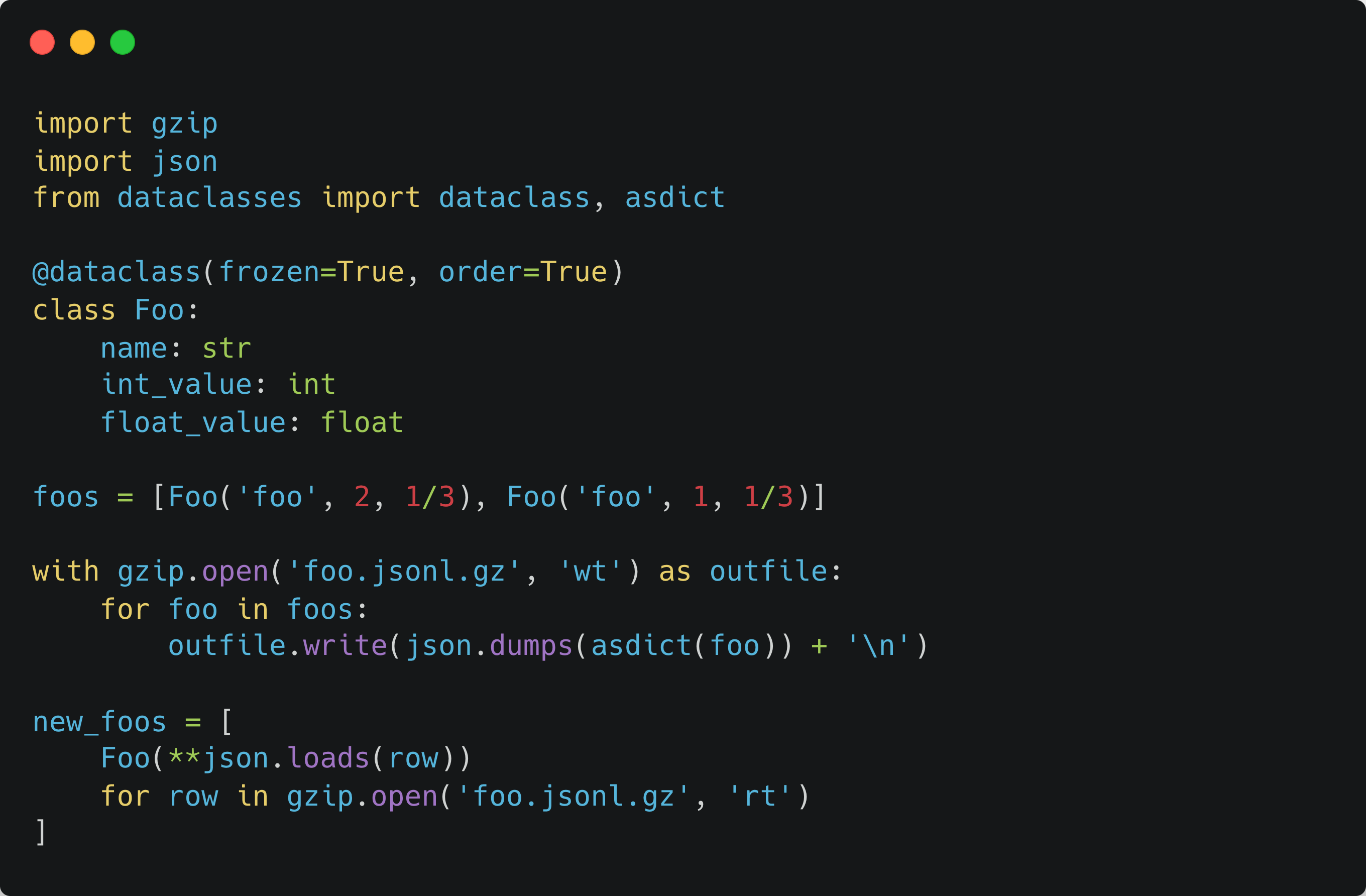
But often, you need to deal with timestamps and dates. That will definitely complicate storage and reload. Let’s take a look at these as well.
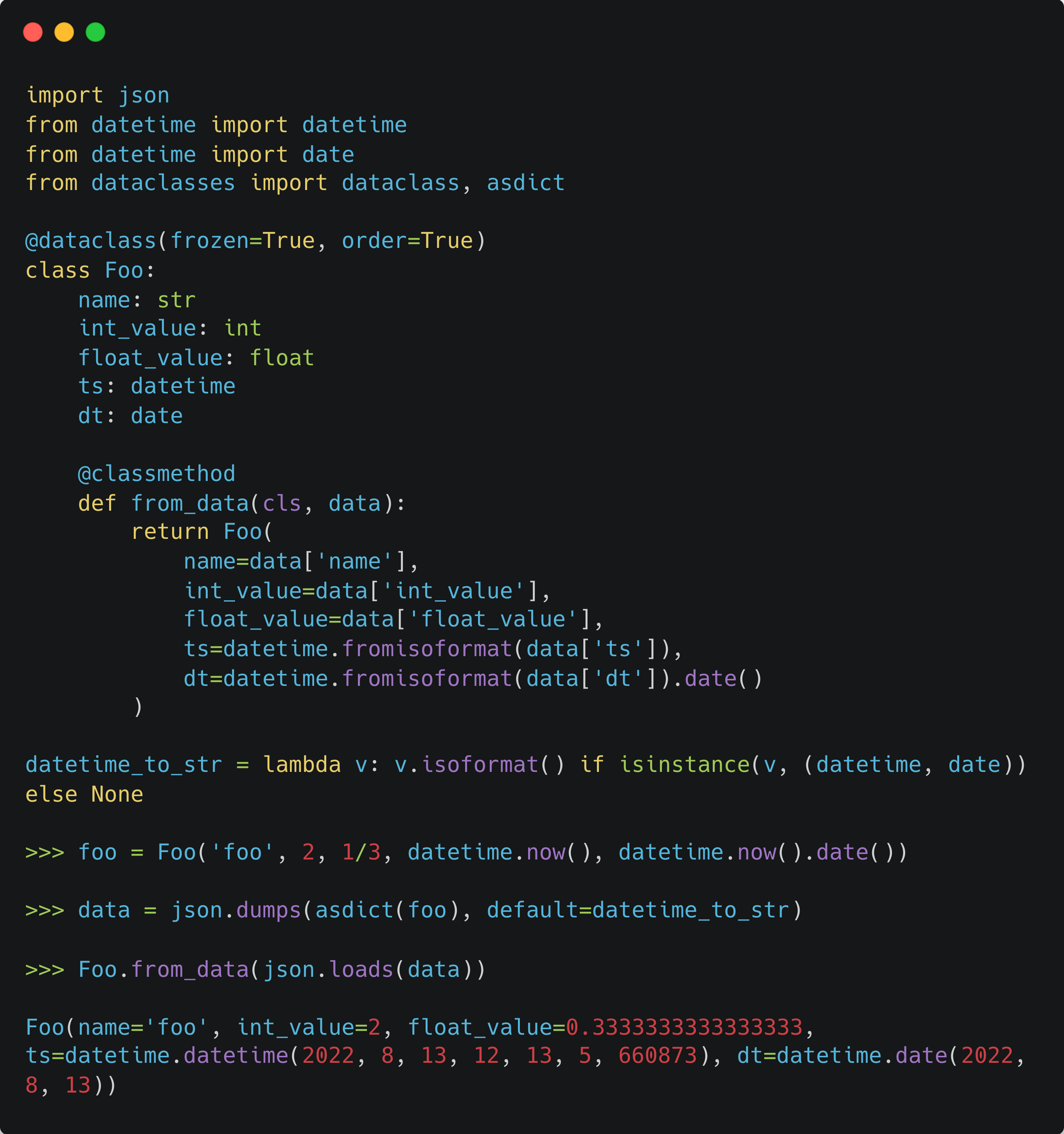
Purely adding datetime to Foo will not work because datetimes are not JSON serialisable. We need to tell json.dumps() how to serialise a datetime when found one through its “default” parameter:

But here is a problem, when loading the data, the isoformatted datetime strings didn’t turn back into datetime. Let’s write a classmethod for this.
What happens if a dataclasses has another dataclass as a property?

As you can see, this works pretty well; the complex class can be used as a key and is also sortable. The order of the properties determines the order they are listed in the class definition.
Here are a couple of more features to consider without trying to be complete:

If you want to use more complex types, import them from “typing”. As you can see, because dictionaries and lists are not hashable, you need to use the “field” class to signal that you are aware of this. Also, you can see how to ignore a property in sorting.
This is great but is there anything better? Yes, there is:
Enter Pydantic

Pydantic recognises the required type and casts it accordingly (Note the datetime/date properties). I haven’t looked at how well it works in general, but if you serialise datetime with isoformat() yourself, there shouldn’t be a problem.
Pydantic provides many more services like type and value constraints checking. It does add some overhead, and of course, it is an additional dependency but worth thinking about it if neither of these are an issue. Because we often work with serialised objects that we did not create ourselves, we like to deserialise according to the above “from_data()” classmethod pattern to have 100% control of the creation, but that’s just one use case.
Summary
In general, switching any domain entity into a dataclass _hugely_ simplified the code and enabled faster changes and a cleaner style in the main service classes resulting in faster progress.
In this article, I collected my use cases and some useful related tips (json, gzip, handling datetimes) and a quick intro to pydantic.
I created this gist with the code: [Gist].
I hope you find it useful, and please share and subscribe if you would like more content on this. Next up: plotly
I don't know that this is really relevant here, but how do you manage feature engineering with dataclasses? So at the beginning of your project you have raw data and you work on defining dataclasses that better represent the domain problem. What's your approach when it comes to the iterative nature of feature engineering. Do you load the dataclasses in a notebook and work on features and modeling there and then later refactor any new interesting features into already existing dataclasses (e.g. add/redefine fields in the dataclasses)?
Thanks Laszlo!
Matteo