
How python programmers save the environment (by making python run faster)?
(Yes, this will be about _that_ nonsense again, now with actual takeaways)

We have all heard by now that compiled languages are fast but slow to write, and interpreted languages are slow but faster to write. Software engineers are the laziest and most impatient people on the planet, so what do they do to get the best of _both_ worlds?
To oversimplify, faster programs solving the same problem consume less energy. If they do it with the same hardware, they will be greener. You can argue about the value of solving the problem in the first place, but that's a different question.
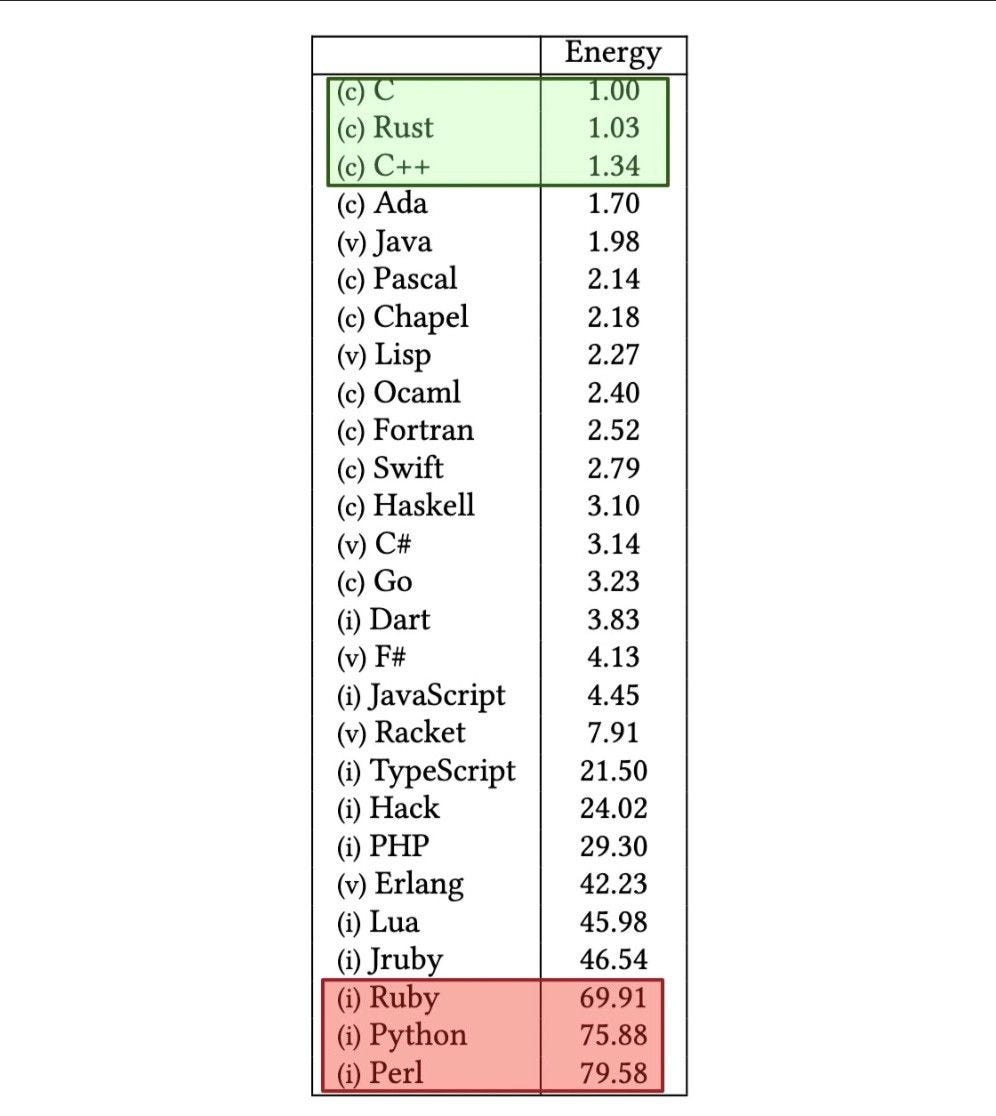
How can you make python faster?
Be pythonic
Python has its own style and for a reason. The interpreter under the hood can exploit efficiencies. If you use python's language elements like list, dictionary and set comprehensions, you can get some speed improvement (just to be clear, not too much). And you have a cleaner code, which is equally important.
Better algorithmic decisions
This is a free lunch. If you can swap list iterations to dictionary lookups, you radically change the theoretical runtime of your code and, through that, your actual runtime. Look out for software engineering practices involving the BigO notation (which is pretty much everything): lookups, searches, mappings, sortings, loops, and iterations.
Memoisation
If you need something multiple times, calculate it once and store it in memory. Next time, it is free! In fact, memory is so cheap; think about how you can use more to make your code run faster.
Parallelisation
Multithreaded programming is pain. To simplify life, python uses "Global Interpreter Lock (GIL)" to stop anything else running while the python interpreter is working. Of course, nowadays, when every machine has multiple cores, this is suboptimal. Python has the "multiprocessing" package to enable parallel execution, which can be simple for "embarrassingly parallel" problems. These programs typically operate on a series of data elements, and the execution order is irrelevant. Mind you, parallelisation doesn't make your code greener because you consume roughly the same amount of energy, just faster. But you will be faster, so I mention it for completeness.
Numba
This is magic. Python is a dynamic, interpreted language. When you run a piece of code, the interpreter translates it on the fly. Because the language is dynamic, it is mostly unable to make assumptions about the types and values of variables. This makes it run extra commands just to be sure, and that is slow.
You can change an integer into a string in the middle of a loop, and using it on a previously integer-indexed array can break your program. Every time you index an array with a variable, the interpreter checks if its value is inside the array. This is time-consuming and wasteful if you already know you are doing the right thing.
This is what numba resolves. You can disable these checks if you write your code in a "safe" way. Numba will compile the code into an intermediate language and executes that language every time you call the function. The result is extreme performance. This is the best solution if you need more speed because you are still writing python code just a bit differently.
Cython
This was the go-to solution before numba. You are essentially writing C code with tools that enable it to interface with python. Then statically compile the code into a binary. Because of C, this will be fast. Of course, it is slower to write C code, but there is always a price.
C/C++/FORTRAN
Python enables you to share memory elements. You can run native code on that, store the results somewhere, and python can pick it up from there. This is not really an option that an average python programmer does in their daily job, but for efficiency, most widely used and non-trivial algorithms are, in fact, written in an efficient language and just interfaced with python. Notable examples are numpy and sklearn or other ML algorithms. This also simplifies maintaining the codebase in one language and writing multiple "wrappers" for other higher-level languages.
Vectorisation
If you don't use numba and repeat the same operation many times on the same data type, you probably can gain much with vectorisation. This typically happens with numerical computations, which consume most of the compute nowadays. You usually use numpy, which uses C or FORTRAN under the hood (through two packages named BLAS and LAPACK). Essentially, instead of looping in native python, you delegate that loop into a compiled static language that takes care of the type and boundary checks for you. Your code will be less readable, but you do gain a lot. You can also exploit if you have multiple cores through parallelisation.
GPUs
This is the ultimate solution to speed up your (numerical) computations. These processors are specifically designed to run parallel calculations on thousands of cores. If you need to multiply two matrices together, each row will run on a different core speeding up the operation thousands of times. Of course, you do need huge matrices to make it worthwhile, which is precisely what Deep Learning has with model (and matrix) sizes in the many gigabytes. It is very unlikely that you will write custom code with CUDA and C++, but both PyTorch and TensorFlow have python bindings, so you can exploit the benefits of GPUs while still enjoying the simplicity of writing python code.
Summary
As you can see, you have a wide variety of options to speed up your python code, given what you are trying to achieve and your circumstances.
Often you can speed up your code by choosing a better algorithm or using a package wrapping for an efficient implementation.
All that while you are still in a dynamic programming environment that enables fast iteration and experimentation.
Is moving compute to a GPU really greener? Is there any study about that?