


MLOps vs DevOps
through Separation of Concerns

One of the most vibrant topics on the MLOps.community slack channel is the discussion around the difference between MLOps and DevOps. One camp is the “you build it, you own it” end-to-end crowd, and in the other corner is the “I just came to make models and minding my own business” team.
In this article, I will attempt to clarify the boundaries between the two derived from the difference between Machine Learning and Software Engineering using my previous article on Separation of Concerns. This enables the reader to decide which responsibilities lie with MLOps and which with DevOps.
Why does this matter?
Machine Learning is a cross-disciplinary paradigm, so, naturally, multiple teams are involved in its execution with different overlapping responsibilities and skillsets. Proper organisational structure leads to problems landing on the desk of the right person with the right skillset and the right responsibilities. At any given point, there is a clear path from the problem to one and only one person to take action. All others are either consulted or informed on the matter but otherwise passive. If this principle is violated, problems can persist without response while the overlapping parties are pointing at each other to take action.
Software engineering is instant
In software engineering, if a test is broken in an update, that is instantaneous, and engineering/ops can react to it immediately either in staging or production. Because software is mostly deterministic, you know that if something went wrong, it would go wrong next time as well. If it happens frequently and has a severe impact, you need to react immediately to stop it from escalating.
Machine Learning is delayed
Machine Learning is statistical; it takes time to identify its problems. A new model might take a long time to reveal its fault because it needs to move a KPI (which is an aggregated metric) away from its benchmark. You need a fair amount of data to evaluate if it is broken or not.
MLOps vs DevOps
Because MLOps is treated as DevOps with some added bits for machine learning, “traditional” DevOps people can claim that MLOps teams are just getting into their business. And quite rightly so. Issues that are shared between MLOps and DevOps should firmly belong to DevOps. MLOps should appear as a customer for them (for example maintaining infrastructure, databases and microservices for deployed models). This enables the MLOps team to abstract the processes that are unique to them.
The core responsibility of MLOps
Because Data Science can evaluate models only statistically, DS teams need to maintain historical evidence of performance and all of the “chain of evidence” to it. This is not a trivial matter and not strictly connected to making models. This is the core responsibility of MLOps: to be able to provide an abstraction layer for the Data Scientists where they can answer historical questions and can deploy their models to production while maintaining the above mentioned “chain of evidence”.
Where is CI/CD in this?
There is an inherent assumption that CI/CD is somehow “fast/frequent/instant”, but that is just a consequence. The primary purpose of CI/CD is that it provides an abstraction layer that enables the end-users (in DevOps the software engineering and in MLOps the DS) to see their intent get into production. Speed and frequency are just resource and process questions abstracted away from the users.
Getting this together
Let’s review the core components of machine learning and what’s the role of DS, Engineering, DWH, MLOps and DevOps in them.
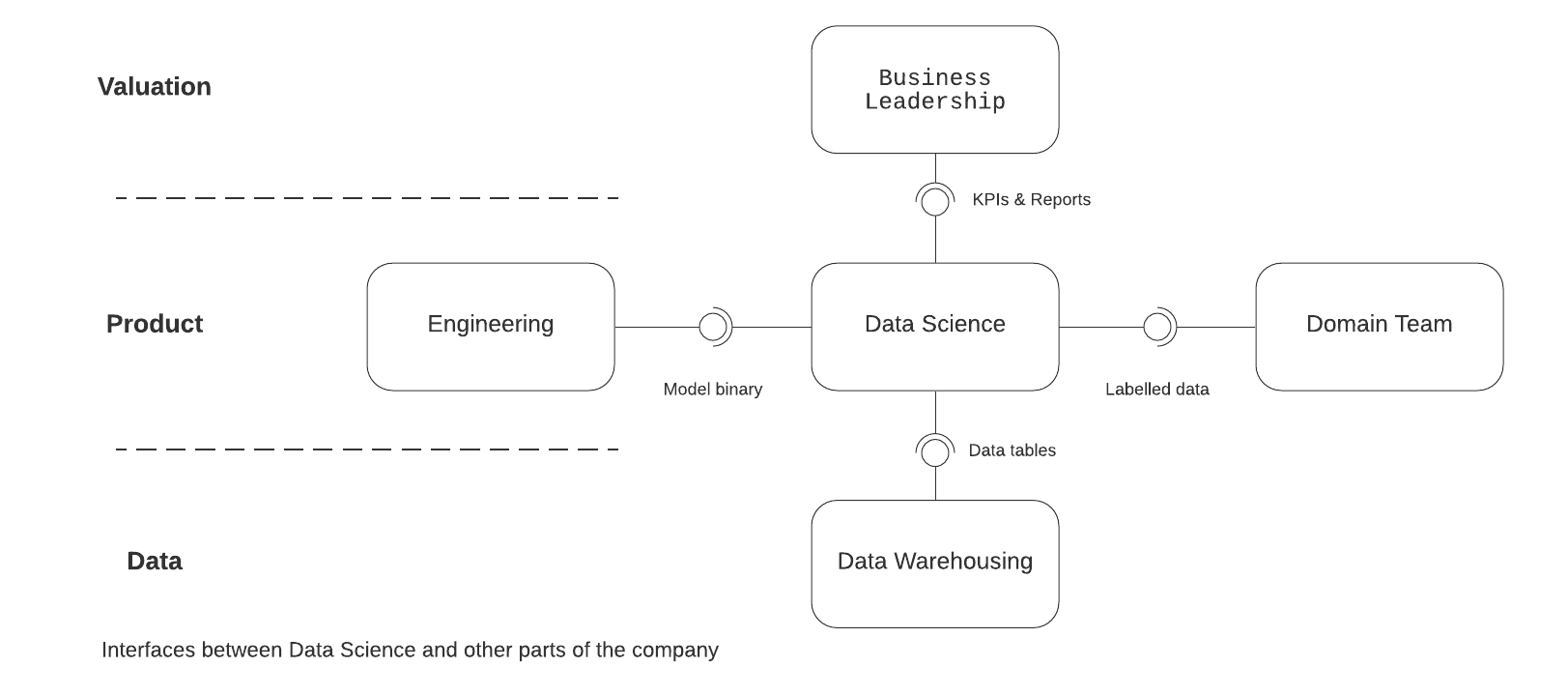
Data for Machine Learning
Models are created from various data sources at various times and checked against other sources at different timelines. This is unique to ML as usually production systems are not concerned about past behaviour. MLOps must rigorously collect and store data from the live systems if DWH doesn’t do it on its own. Of course, they appear as clients to DWH using their data upstream, so collaboration is a must. Various data security, lineage, permission issues belong to MLOps as well.
Modelling
Modelling and evaluation are an extremely compute-intensive process at peak times. This is also unique to ML so MLOps must be in charge and appearing as a client to DevOps who is maintaining the entire compute platform for the company. Modells should be written in production quality by the DS teams and not be rewritten by Engineering.
Deployment
During product development, Engineering and Data Science agree on an interface between them at their abstraction level. Both of them are in communication with their respective Ops team. The deployment should be treated as a common engineering problem apart from the need to maintain historical evidence. DevOps teams must handle instant issues around deployment in production as they are not statistical problems.
Monitoring
Monitoring means collecting evidence regarding long term model performance and not instantaneous activity (see point two in Deployment). MLOps should be in charge to record which models are live at which point in time and what is required for this information to be stored. During this, they negotiate with Engineering, DevOps and DWH.
The actual act of monitoring can happen on any data visualisation tools that can connect the collected source. Again it must be emphasised that this is a long term process and should be performed by DSes (and not MLOps) on an ongoing basis.
All of the above discussion is about roles and not people. Of course, in a small company, multiple of those above can be performed by the same person. But it is still essential to know that when an issue arises, what “hat” must one wear and what to do.
Summary
Machine Learning is statistical, and evaluation can only happen over time. MLOps is concerned with maintaining that long term chain of evidence and provide an abstraction layer to this for Data Scientists. All other issues belong to DevOps who maintain production systems contemporaneously.