
Mocking OpenAI - Unit testing in the age of LLMs (Part One)
2025-02-23

I haven’t written for a while because I was heads down on a GenAI project. But recently I ran into something which I think is noteworthy.
Just because everyone uses LLMs and code generators, it doesn’t mean we don’t have to write unit tests. The purpose of the tests is to verify that assumptions about the code outside of the LLMs are still correct.
LLMs are notoriously flaky; run them twice, and they give you two different results. They are also slow. You want to test many assumptions, you will have to wait a long time. They are also a complicated dependency of your code with many assumptions.
Unit tests have three important characteristics:
Fast
Deterministic
Targetted
Now, if I see it right, all three of them are broken if you want to test LLMs. Therefore, something must be done to the code to avoid this.
There are two solutions:
Mocking (this article)
Faking (Part Two) [link]
[Edit]
Here is the repo for the code: https://github.com/xLaszlo/mopenai/
Before we can get on, we need to create some code to test:
OpenAI Service
(I use async throughout the article; if you are not familiar with it, please mention it in the comments. I am planning to write about that as well, but I need some encouragement).

Here, OpenAI is wrapped into a service class that manages the client and directs requests to the API. We also use the popular package “tenacity” to simplify retries. In critical components, we typically write out the retry logic to have maximum control over it. However, that is pretty tedious and adds a lot of extra details to control, so it is reserved for a few places. The above decorator is just too easy to use. As you can see later, it also makes testing more difficult.
Main.py
The main program is rather simple; we instantiate the service and pass a command line argument to it with “typer”. Note the async-specific code.

Tests
What do we test here? This is a simple example so the service doesn’t do anything else apart from returning the value. The goal is to:
See that OpenAI is called
Returns the right value
In the above setup, the only way to do this is to mock the OpenAI client (see Part Two for alternatives): replace it with a fake function that returns something we want and then filter that value downstream, and when it is returned into the test, check the return value to a reference value.
Test Setup
I use “unittest” tests, which were adopted from JUnit, a popular Java package. Again mind the async specific code:

Here, each class is a set of tests which can have a common setup and teardown to simplify testing code. The baseclasses also provide a long list of assertion methods (compare two dictionaries, lists, “almost equal” for floats, etc,) which simplifies and, therefore, encourages better testing practices.
Typical tests have three stages (often called Given-When-Then):
Given: setup, what are the prerequisites of the test
When: run the code
Then: assert the results of the run
Let’s write a test then:
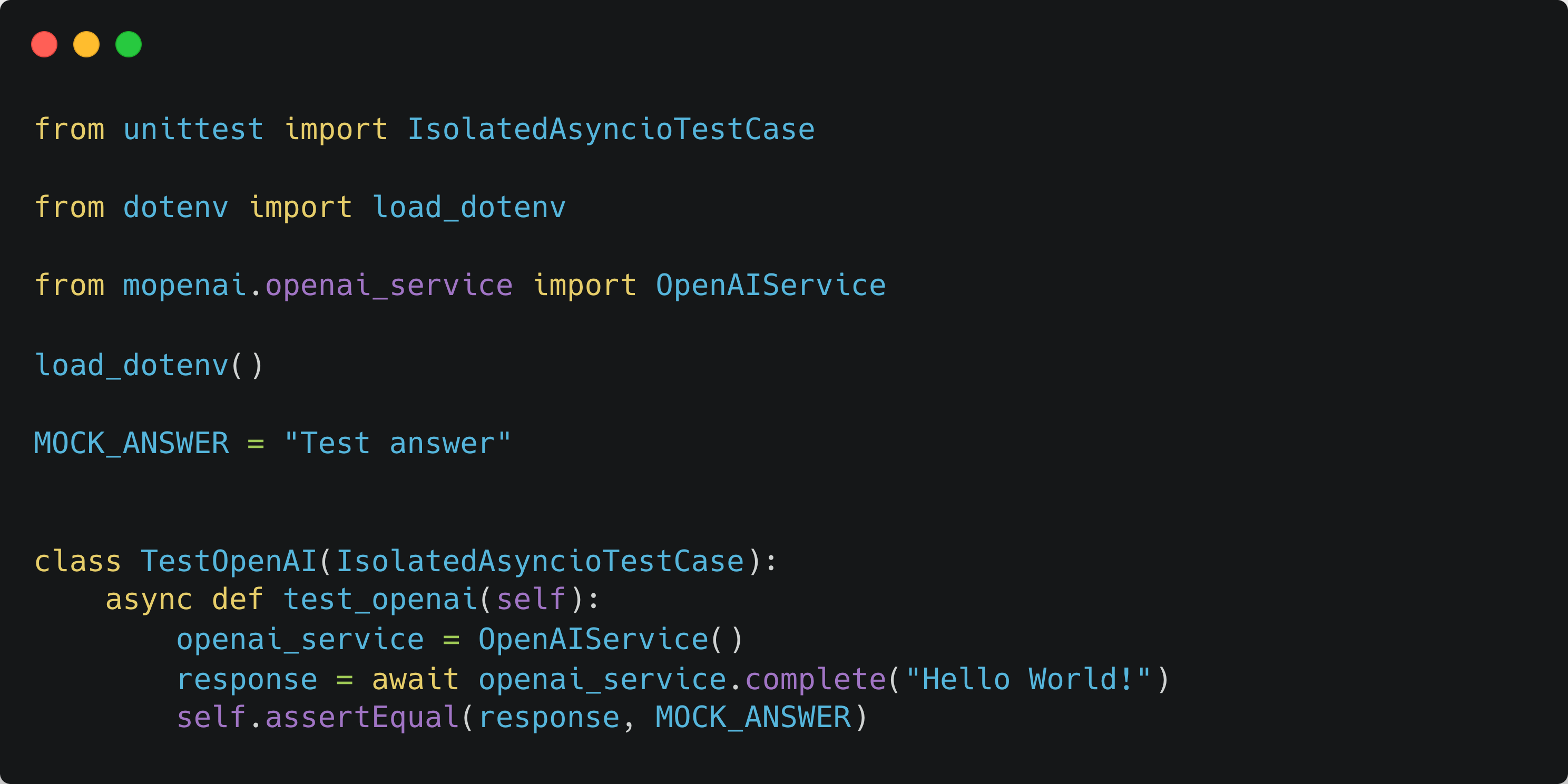
We have three lines in the test:
Instantiate the service (“Given”)
Call the service (“When”)
Assert the response (“Then”)
What’s wrong with this? First, this code will run automatically in GitHub actions, pre-commit hooks, and occasionally between two edits by the contributors. From the load_dotenv() function, you can assume this needs the API key, which means each run will cost money. You have complicated business logic downstream from the LLM; you will write a lot of tests, and each will call the model, which will cost a serious amount of money. Not only money, but you will also sit there waiting for the response, which means you will lose time. The reaction to these is to test less, leading to brittle and tech-debt-ridden code; tests help write better code because you can run your code more, leading to tighter feedback loops.
Solution: Mocking
So what’s the solution?
Let’s not call OpenAI and instead just make something up…
Unit tests are supposed to be localised; they should test exactly one assumption. When you test your own code and call OpenAI, you actually test them as well. As in “Are you still there?”. Now, of course, if they are not, that’s a major problem, but it has nothing to do with whether your code is buggy or not. So better to avoid this.
The solution is to “mock” the client. Replace it with code that, for specific inputs, behaves (read: returns) the same way as the real deal. This code is so simple that we can accept it as “bug-free” (famous last words, but that’s the intention). If something breaks in the mock code, it will be obvious (again, famous last words).
Mock httpx with respx
But the question is how? It is easier said than done. OpenAI has a notoriously complicated and ever-changing API, and the client is hardcoded into the service class. So the only way to do that is mocking (replace it in test time with something else).
But that’s not easy either. After searching the internet and discussing it with ChatGPT (that’s pretty meta, isn’t it), I found that OpenAI recommends mocking the underlying “httpx” client (a better “requests” package that handles HTTP calls).
The OpenAI client is a code-generated module from the OpenAI API definition, mostly just pydantic classes which then manage calls to the API through httpx so this makes sense.
Luckily, httpx has a dedicated mocking library called “respx”, so you don’t need to manually figure out what the mocking strings (the import statements to replace with the fake code) should be.
All you need to do is to use that as a context manager and some extra code and you are good to go.

As you can see, we replace both the GET and POST calls as well (OpenAI uses the POST one) and then do assertions if only one is called. (This is partly for demonstration reasons here).
When we call the OpenAI client, the arguments are formatted and passed to httpx; this was replaced by respx, and based on the protocol, we call one of the side_effect functions, passing the request object to them. The return value can then be returned to the OpenAI client as if it were coming from the Internet, and it can wrap it into the client-specific objects.
[Edit: Thanks, Han, for flagging that I was less than clear here, I also shared the repo above]
The original call chain is the following:
Code calls service.complete()
Service calls client.complete()
Client calls httpx.post()
Httpx returns some json (converted to Python dictionaries)
Client converts dictionaries into Pydantic classes
Service extracts the response from the class and returns
When mocking, httpx is replaced with respx and httpx.post() with the function specified in side_effect. So the new call chain is (changes in bold):
Code calls service.complete()
Service calls client.complete()
Client calls httpx.post() (which is replaced by respx)
respx calls side_effect
side_effect returns Python dictionaries
Client converts dictionaries into Pydantic classes
Service extracts the response from the class and returns
The only thing left is the mock function:

As you can see, we specifically capture the request by the URL. You can have more complicated logic here if you have multiple calls in the same test.
We also throw an error if we cannot match the request to anything we expect. This can be a potentially runaway test and worth being deliberate.
It’s worth starting with the exception to see what is happening and then adding the real responses individually.
What if you don’t know the response format? A typical trick is to instantiate a client here, call the same API as the actual code, display the response, and then replace the hardcode with the mock function. But ultimately, you need to figure out the low-level response structure from the OpenAI definition. I found that the “curl” version of the documentation is the most helpful in this.
One more problem: tenacity
Tests should be as fast as possible. Retry logic shouldn’t retry immediately as the previous problem might still persist. This is a contradiction.
Clearly, we don’t expect the mock function to cause any problems, so the reason to use Tenacity in tests is mute. But we can’t just rip it out from the code if we are testing?
So we must also mock that to be “pass-through” and essentially behave like it is not there.
The problem here is that tenacity is a decorator. It can’t be just mocked as when you run the test; it already decorated the tested function. So, we need to mock the class that manages the retries:
The following changes will achieve this goal.

Remember again the async code. Instead of the wait/retry loop, the new version just calls the wrapped function. If our business logic past the LLM call has an error, it will fail on the first try.
Summary
The following takeaways were discussed:
OpenAI as a service class
Async paradigm framework with “typer” CLI
Unittest style Given-When-Then tests
Mock OpenAI client through mocking httpx with respx
Mock tenacity.retry
I hope you find this article useful; as LLM projects become more complicated outside of the actual LLM, code and testing will be more and more important aspects of writing solutions. This article is intended to help this.
The next part will be about doing the same with fakes (or doubles and spies), a type of class that can step in instead of mocking. Please comment if you are interested.
Also, if you would like to read more about async programming, which is crucial if your code has long waiting HTTP requests (like all LLMs).
I’m not familiar with async (commenting for encouragement)
Is there a way to not use images for code?
Makes it not copyable.
I wanted to copy to ask gpt what this paragraph means
"When we call the OpenAI client, the arguments are formatted and passed to httpx; this was replaced by respx, and based on the protocol, we call one of the side_effect functions, passing the request object to them. The return value can then be returned to the OpenAI client as if it were coming from the Internet, and it can wrap it into the client-specific objects."
It was tough relating this to the code block above. I understood about 20% of it