
How to solve Machine Learning problems for production? (Part 1)

Machine Learning in industrial settings operates in a different context than in academia. To increase success, one must deviate from the original Waterfall-like method of conducting modelling and adopt a more flexible approach. This is what we describe as “Lean in ML”. In this first part, I will set the scene and describe what good problems for industrial machine learning are, and in the next part, I will advise the thought process of how to solve these problems. Please follow me on Twitter to get notified for the second part.
Context of Industrial Machine Learning Products
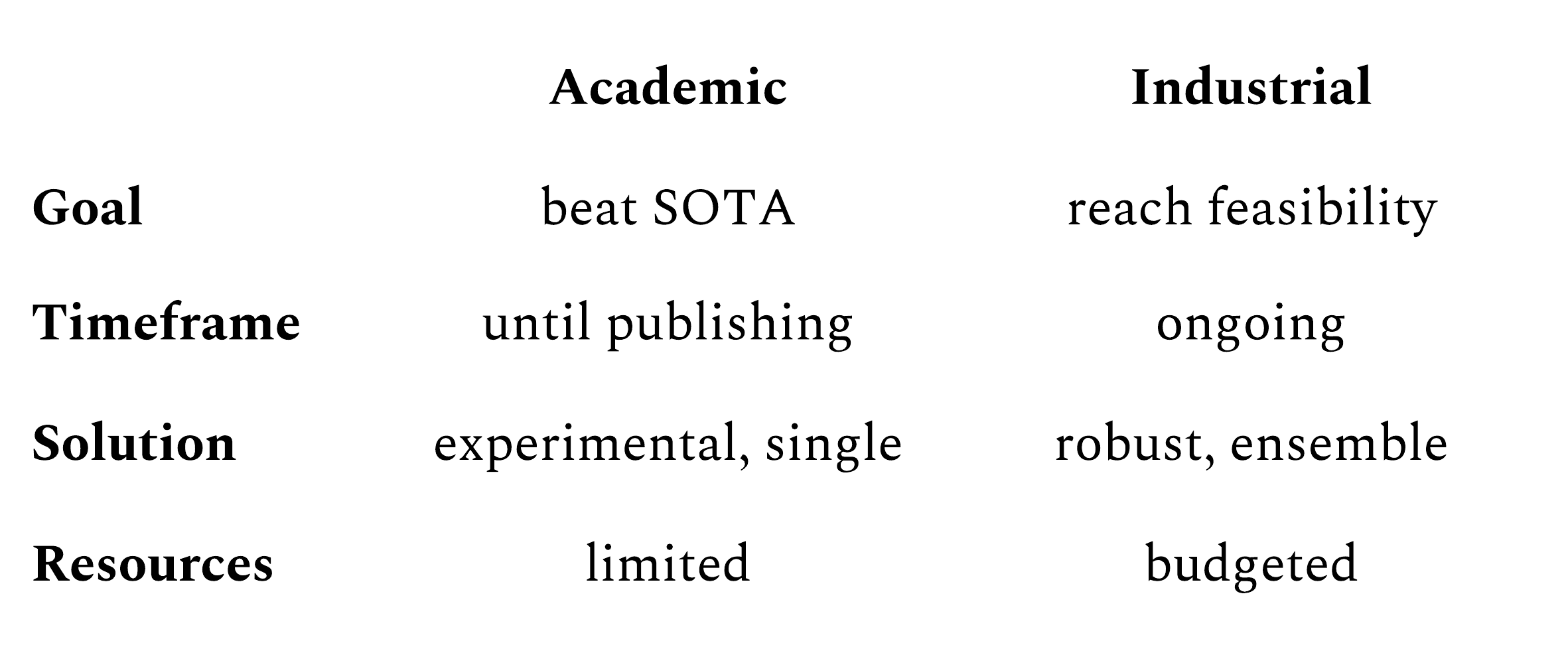
The context can be described by four major factors: goal, solution, timeframe and resources. In machine learning research, the goal is to beat the SOTA (State-Of-The-Art) performance to show that a single novel approach is better than previous ones and eventually get published. The timeframe of the problem is limited by the publication date. Available resources are also limited because SOTA only needs to be beaten by a small margin, the solution is limited to a single technique and the time limit doesn’t mandate infrastructure investment or long term maintenance costs.
The opposite happens in the industry where the goal is to reach a minimum target performance that makes the whole solution feasible. Usually, ensemble technique needs to be used because the performance target is beyond the reach of any single solution. The part of the problem that cannot be solved at any cost needs to be patched by manual intervention that adds to the repeated costs. This eventually successful product requires ongoing maintenance after deployment, which requires budgeted ongoing costs and an infrastructure the whole product is built on.
Industrial Machine Learning projects often fail for confusing the two cases above and not committing enough to the second one, attempting the first one and fail when the difficulties stemming from the differences between the two halt progress.
How to select ML projects that you can commit to?
A good problem for Machine Learning has certain features that make it valuable to be solved, so the company is willing to commit to the process of solving it.
It involves lots of manual labour, especially lots of micro-decisions. Automating part of this is the main benefit of the project. Further advantages are relieving employees from doing chores and focusing on edge cases and potentially expanding the scope of the project. This also enables them to take a broader look at the whole issue and make a more coherent, quantifiable and scalable approach to it.
Hard to describe, hard to simplify domain knowledge. Traditionally automation focused on rule-based systems where these can be implemented into a system and verified to pass a specification. In the absence of these, one can turn to Machine Learning for help. One sign of this is if the employees express their micro-decisions through subjective language but cannot form rules when pressed.
A lot of contextual data is available. Given that the domain experts themselves cannot express the rules, these must be distilled from the context of the decisions through the modelling process. This requires an adequate description of this context by the available data. The question to answer is if all information is recorded that the domain expert consciously or unconsciously takes into account.
Summary
The difference in Machine Learning between academic and industrial environments:
Good machine learning problems:
Involves lots of manual labour, especially lots of micro-decisions
Hard to describe, hard to simplify domain knowledge
Lots of contextual data available
Please follow me on Twitter for Part 2: