

Separation of Concerns in Machine Learning
Separation of Concerns in Machine Learning

Decomposition is the most important system design and problem solving principle. Because of its importance it pops up in many fields and has many names: Separation of Concerns, Single Responsibility, Bounded Context, Interface Design, Contract Programming, APIs, Microservices and these are only in software engineering! I am sure the list goes on if we go into other fields as well.
Unless we perform decomposition on the problem at hand, we are attempting to solve all problems at once. Considering the limited cognitive capabilities of humans this renders any solutions unfeasible. Lack of decomposition greatly frustrates team work, because without clear responsibilities everyone is in charge of everything, so nobody actually is. This will result in one or many participants to grow frustrated and disengaging from the project ensuring its failure.
Enter Separation of Concerns
By decomposing the problem we mean carving out a specific subproblem and declaring all other parts of the project solved. The team in charge of implementing the solution can focus on a single part of the whole picture. They are concerned with three things:
Implementing the solution for the subproblem
Define what services they expect form the rest of the system
Define what services they provide for the system
The latter two together is called the interface or boundary of the subproblem. And this is the their only concern regarding the project, they are separated from the rest of the project by the boundary. As the interface connects the local solution to the global, it must be carefully negotiated with the rest of the project team as it is much harder to change it later than the actual subsolution. For example in my previous article on the primary advantage of Machine Learning, labelled data acts as an interface between the domain team and the DS team and everyone understands how difficult it is to change labelled data.
How to use this in Machine Learning?
To apply this in ML, I will invoke the three areas described in my previous blogpost on decomposition of the data driven enterprise these were: State (Data), Policy (Product) and Reward (Valuation).
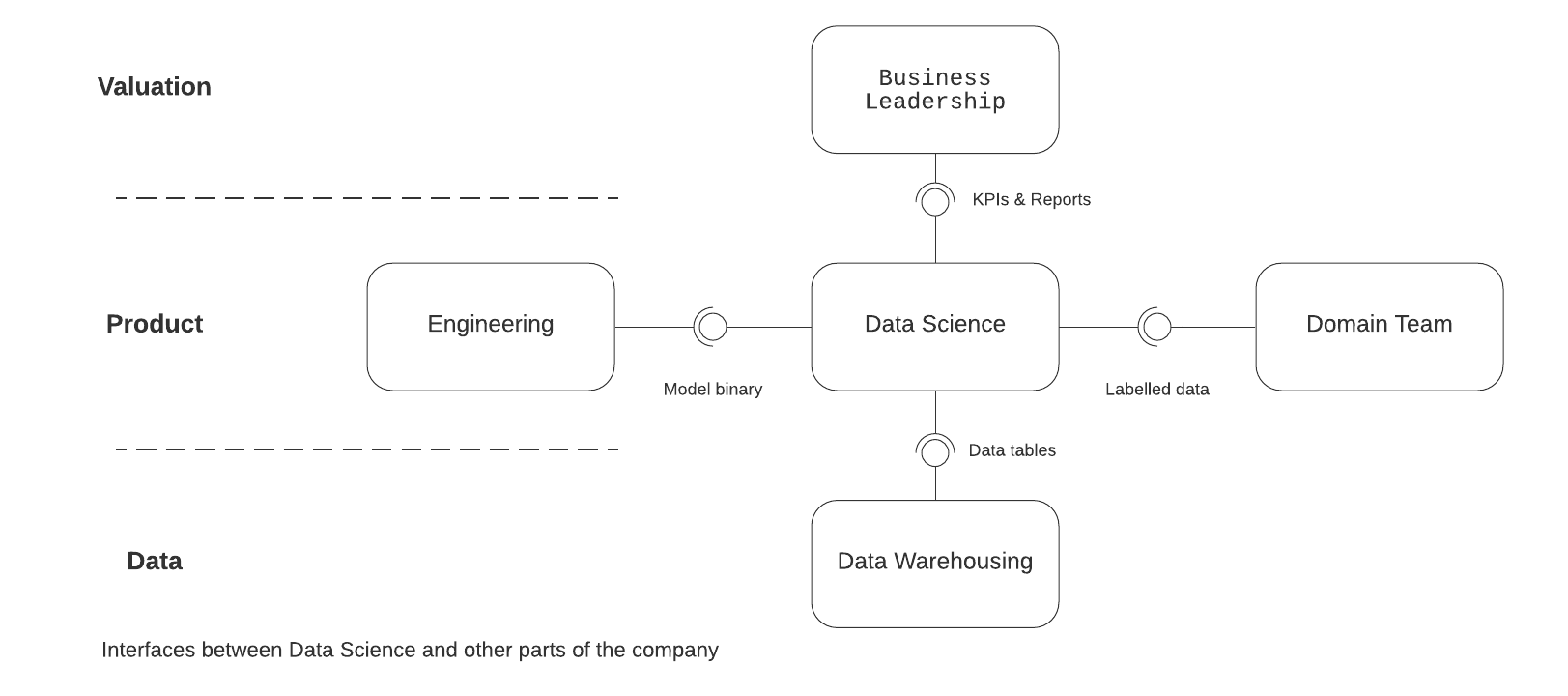
Data Science is used in all three of them in various forms so three boundaries must be defined. To successfully build productionised ML systems DSes must cooperate with the natural owners of each of the areas and define clear concerns and responsibilities. These owners are:
Product: Engineering and the Product/Domain Team
Data: Data Warehousing and Business Intelligence
Value: Business Leadership and Finance
Let’s review each area and how DSes cooperate with them and how the separate concerns are distributed:
Product
This needs to be separated into two phases as the DS team acts as a conduit between the domain team and engineering regarding the ML solution.
First the domain team and the ML team agree on the specification in the form of labelled data and a set of domain specific quantitative performance metrics that verifies that the solution actually solves the problem. This data can come from the DWH and the DS team can help the domain team but the domain team owns it as they are in charge of the problem.
Second, the engineering team builds the productionised environment the models are running in but not the models themselves. The boundary between engineering and DS is the API of the model, namely the input/output (prediction) data. Performance and error issues regarding the model are a concern of the DS team. This way the engineering team does not have to reimplement the model which is clearly outside of their competence. Defining telemetry is part of the API (this is very important in terms of monitoring different model versions).
Data
DWH/BI is responsible providing the data on the performance of the models. This is usually created from logs regarding the productionised operation of the model and converted into tables storing relevant information. DS appears as a customer here where they are focusing on data lineage and recoverability of which version of the model was in production at which point in time. The interface between them is the specification of the required data and the database tables themselves. The actual performance of the model (offline or in realtime) is the responsibility of the DS.
Value
Business Leadership must express its goals, expectations and constraints to the DS/Domain team clearly and transparently. This is their boundary which is completed with regular reports regarding the health of the project. The key here is transparency and most interfacing is organisational.
Benefits
Separating concerns in the above way have multiple advantages. Each participating parties operate inside their competence: they are just doing their regular job and the ML project appears as a customer. All innovation and risk is allocated into the project team where domain experts (who understand the problem) and DSes (who understand the solution) work together in closed loop iterations. Both of them again are concerned only with their own strong skills. Business leadership defines and expects transparent reporting.
Thank you for reading my article, please provide feedback and subscribe/share!