
How to solve Machine Learning problems for production? (Part 2)

In the first part, I described the context of how academic and industrial problem solving differ. The primary differences are the timeline of the solution and the complexity. When you prepare to solve a problem that will be part of a product, you can expect that the solution will be with you for an extended period. You will also have external performance metrics which you must surpass otherwise it will be deemed unfeasible. These conditions will create challenges but also opportunities, and given the longevity of the product, there will be time for more involved solutions.
Step 1: Decompose
Given the performance requirements of most industrial environments, the whole problem is probably too large to tackle at once. If for example, the model needs a large amount of labelled data, producing all of it at once would create significant opportunity risk because the viability of the model will be only found out when all the resource was spent on the labelling task.
Based on domain knowledge most problems have features that decompose a holistic task into smaller subproblems: For example in case of news the location where the news happened based on the source of the information or the language it was written. If there are multiple choices available, then select the easiest one first. At first, try to solve this problem alone and only if it is tackled successfully then attempt the most complicated looking one. These two will “bracket” the rest of the partial solutions as the effort for all of them will be between them.

This ordering will also help maximum learning efficiency as attempting the easy case will recover problems that you missed in the planning phase and trying the hardest one will reveal issues that are too obscure for anyone to think ahead.
Step 2: Solve with augmented workflow
Now that the modelling problem is clarified, you can go through your usual modelling steps with one thought kept in mind. The modelling problem is not an arbitrary standalone statistical task. It needs to fulfil a business goal, and you can use the business’s resources to achieve this goal. If the modelling task falls short from the feasibility requirement, you can design a workflow where the problematic cases are directed to experts to solve. Given that the problem you are working on already has a process inside the enterprise, you essentially select the “hard” cases for the already engaged workforce and automate the chore ones.
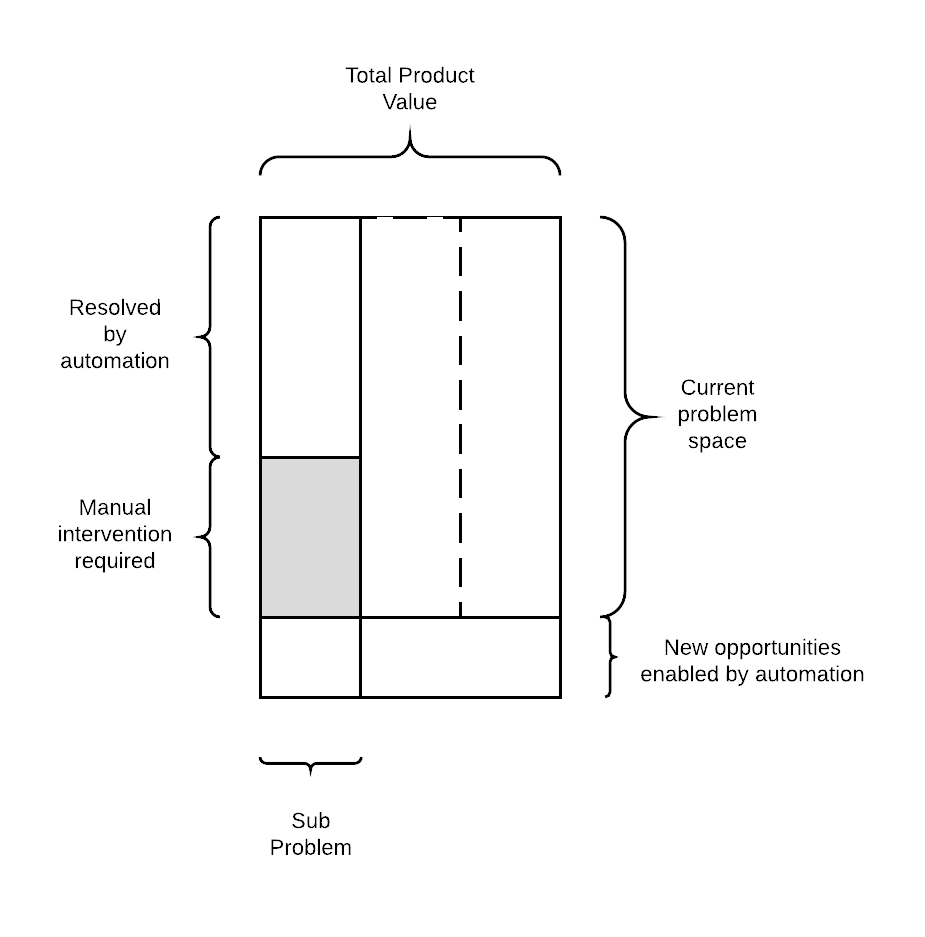
The business viability is judged on the overall cost of the workflow, namely: current cost of personnel vs risk from automation mistakes (if any) plus remaining labour costs. There is also an extra component; some opportunities are unexploitable because the cost of manually handling them is loss-making. Given the automation, the price of dealing with these drops and present additional revenue.
Step 3: Iterate
Once the workflow is in production, you can start planning the next steps. You have the choice between tackling another subproblem (the hardest one, more on this later) or improving the current one. Identify new automation opportunities from the insights gained in Step 2 and carry on updating the model. These insights are usually coming from the domain experts working on the manual part of the workflow. Essentially the goal is to automate different aspects of their jobs so they can move on to harder subproblems or edge cases that resist automation.
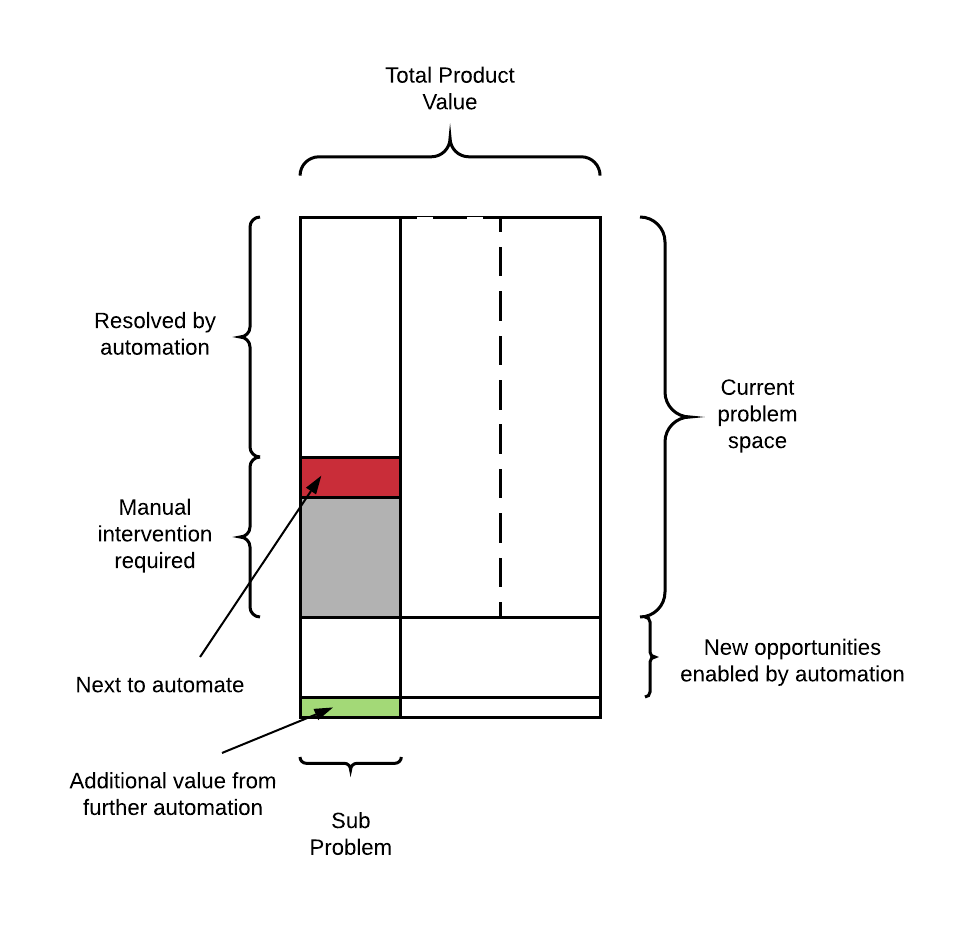
The benefit here is evaluated by comparing the net savings on existing labour costs and the risk of modelling mistakes. Further value is unlocked by the increased amount of newly feasible opportunities depicted with the green area on the diagram above.
Step 4: Next problem
It is much easier to try tacking the most challenging problem once an already existing workflow is in place. That can act as a template, and the team can reason the difficulties of the new task against that one. Also, the unforeseen insights at the planning stage that was gathered in the first solution can be incorporated into the new one.
This time, the product team has a considerable routine, and they can focus on more abstract business problems rather than implementation issues. This is a much-needed help for them, given that the second problem was judged harder for some domain reasons. They benefit from having a single focus on the problem rather than on technical issues.
Summary
Once the two subproblems are solved, the team can bracket and plan for the rest with high confidence. If the implementation enabled parallelisation, the rest of the cases could be attempted at the same time with various organisational parallelism and specialisations. This is the time when the organised attempt pays off as at this point the team as a whole has a considerable routine in executing the necessary steps and the way they solve problems will be part of the enterprise’s institutional knowledge.
I hope you found this article useful. We will soon release an eBook with operational best practices on the topic; please follow me on Twitter for updates:
@Laszlo Sragner Enjoying this series of articles very much from a PM perspective, however do you think you can post more on the technical side of ML products? e.g. how to set up and curate DS/ML repos, packaging models, etc... would love some of your opinion on best practices on that side