


You only need 2 Design Patterns to improve the quality of your code in a data science project
2021-11-01

[Edit]
Join our Discord community, “Code Quality for Data Science (CQ4DS)”, to learn more about the topic: https://discord.gg/8uUZNMCad2. All DSes are welcome regardless of skill level!
[Edit]
Design patterns are a popular subject, and you see them mentioned everywhere.
But often, when you read an article on design patterns for data scientists, you face a long list with typical examples taken from popular sources. The problem is that most of these examples are for “real” software engineers and don’t apply to data science workflows.
For data scientists who just started to think about code quality, I cut down the list to the two most relevant ones to make things easy. These are:
Factory Pattern
Strategy Pattern
At our previous company, we used these everywhere to maintain production-grade code in NLP while still having the flexibility to experiment and solve unforeseen issues.
These will bring you a lot of value at a minimum cost, you can use them early on, and you will have plenty of time to study others when you move up the learning curve.
What are design patterns?
Design patterns are templates for how to solve common problems that can be used in many different situations. It is not a concrete solution or source code. These common patterns help comprehension of the codebase and build a language to communicate easier about solutions.
How are design patterns used in data science?
The main problem in data science projects is coupling.
You are writing experimental code, but you are expected to deliver production-grade conclusions. If your solution is coupled, it means that you need to rewrite a large part of your code each time you want to try new options.
If you can decouple from concrete decisions in your solution, you can construct experiments by declaring them instead.
What is coupling?
Coupling is the interdependence between different parts of your codebase.
If you want to change something about your code and you need to do a significant amount of rewrite at seemingly unrelated places, then you most likely have coupled components. If you struggle reusing parts of your code in different contexts, that also signs that the part to be reused is coupled with a concrete context.
The two main components in any Data Science project are data and algorithms. The Factory pattern will help you decouple data IO, and the Strategy Pattern helps you decouple algorithms.
Let’s take a look at this in an example:
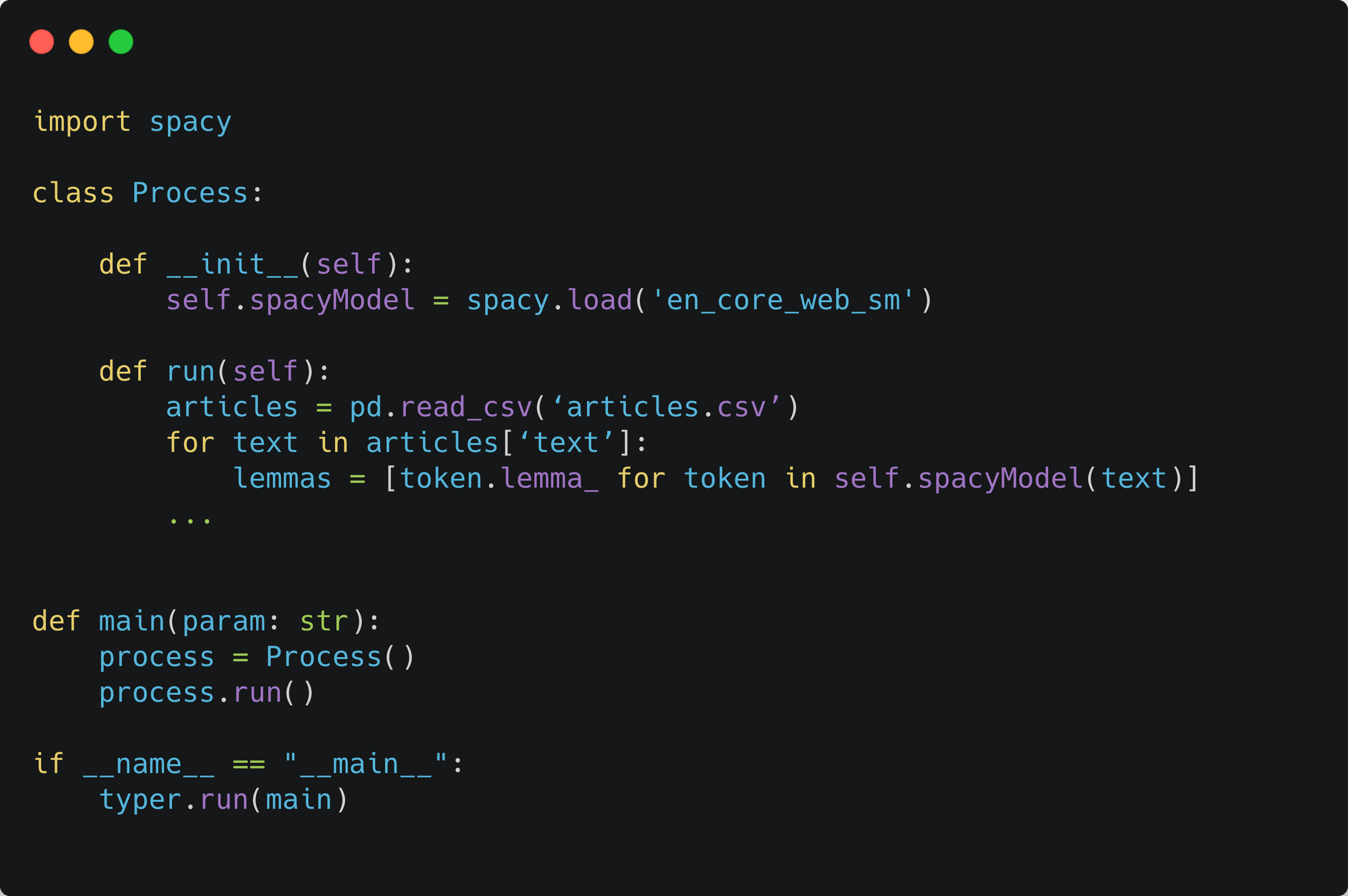
This program loads some text into a pandas dataframe and calls spacy to turn these into lemmas. Notice that it was already refactored according to my previous article in Part 1.
Where is the coupling? If you would like to load the data from somewhere else, you need to write into the run() function. If you would like to use a different NLP tool, you need to write into this code. If `Process` is used anywhere in production, you need to start a change request notifying the product owners. The alternative is to keep working in a branch, but this isn’t ideal as you might need to rebase frequently to update it with recent changes.
The best would be if you can somehow not make these decisions about pandas and spacy when you write Process, but only later when you use Process. The person who maintains the production code can decide independently from you how to carry on while you can experiment with alternatives.
The Factory Pattern
In its simplest form, the Factory Pattern is about generating objects.
Its primary role is to separate the objects from their creation. In Data Science, this usually means that using data is decoupled from where is this data coming from. Employing the pattern allows you a layer of abstraction in your computations where you can work with classes but don’t need to worry about their origin.
You implement the Factory by declaring an interface. The caller - your code where you want to use the objects - uses this interface to get the data but is not aware of where the data is coming from.
The implementation of each Factory deals with all the necessary details about how to get the data, how to convert it into objects and return them. This is a lower level of abstraction as you are concerned with concrete details, for example, filenames and database credentials.
This facilitates code reuse by declaring your computational code with different data loaders (database, file, other formats, synthetic data). The only thing you need to ensure is that each return the same class. You can also test this code by writing data loaders that return predefined objects.
Let’s refactor the above example in four quick steps:
Step 1: move loading code to a new class
Step 2: add loading class to the constructor
Step 3: refactor loading to use new loader
Step 4: create a loader at usage time

Run the tests written in Part 1 to check if there was no change in the behaviour of the code.
Notice that get_articles() do not return articles, but a dataframe and run() uses strings instead of domain classes. This can be a problem if you would like to have other data about articles as well. This is a “code smell” called “primitive obsession”, which will be mentioned in Part 3 of the series. Subscribe to be notified about it.
Now you can extend your code without modifying `Process`. For example, if you would like to load the articles from a database, just create an `SQLArticleLoader` class and plug it into `Process` at creation time:

The Strategy Pattern
The second major problem is deciding on which algorithm to use in a concrete implementation.
Often you face choices that cannot be decided early on and need to be changed later. If this happens, you need to rewrite the main body of your code because algorithms are typically tightly coupled in it, leading to potentially breaking changes.
To help with that, one can abstract out the algorithm with a Strategy Pattern. Just like in the Factory Pattern, this starts with an interface. Instead of calling the algorithm directly, you will wrap it with a class and call a class member function to get the output. Any input is passed to the member function, and if generic parameters are the same for all calls, you can add them to the constructor.
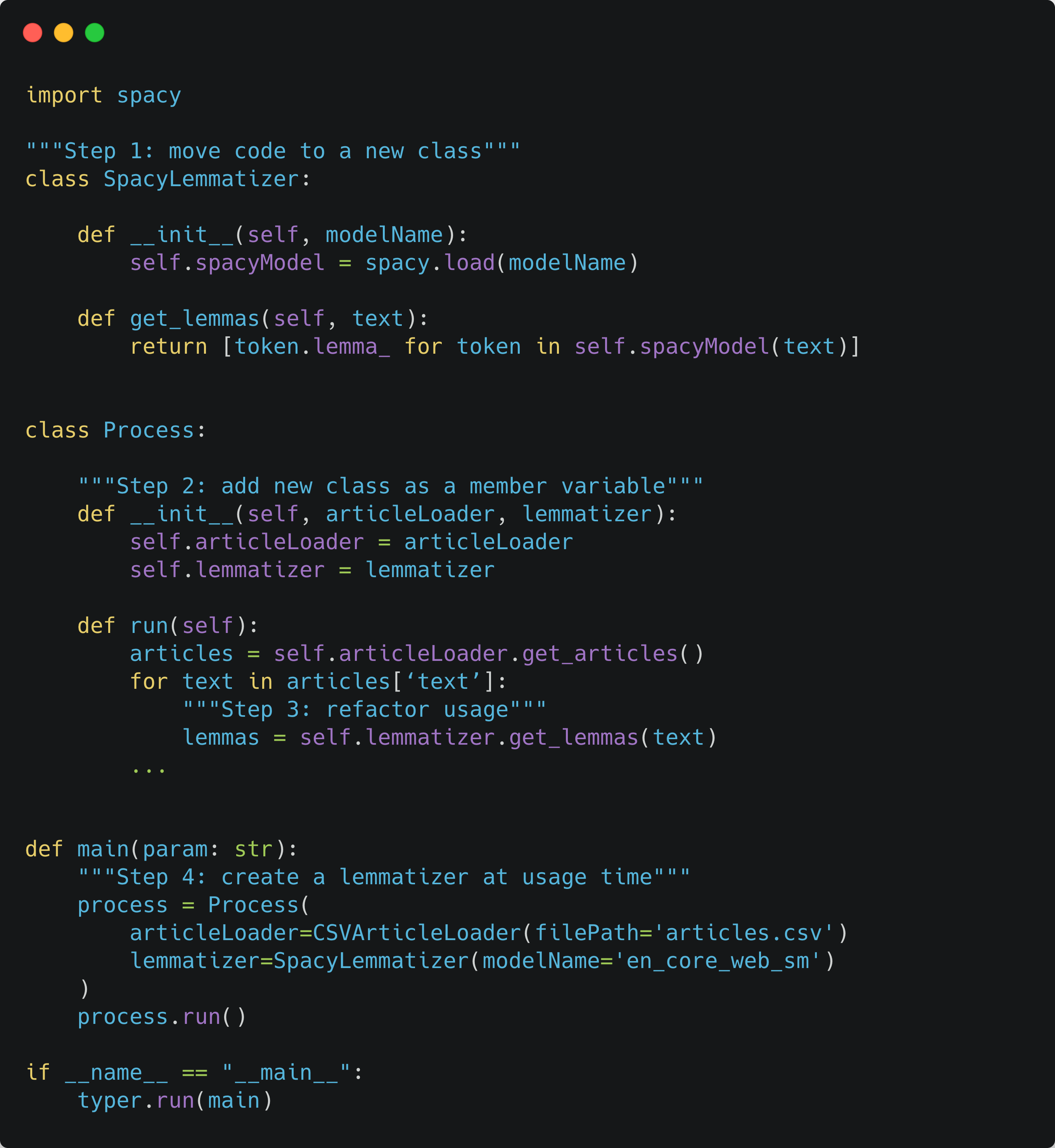
Let’s see how this works in our example. The steps are remarkably similar to the Factory, which is a good thing, one less moving part to remember:
Step 1: move code to a new class
Step 2: add a new class as a member variable
Step 3: refactor usage
Step 4: create a lemmatizer at usage time
Now let’s see what happens if you decide that you would like to use StanfordNLP’s lemmatizer instead of Spacy’s. They are quite different in terms of interface and implementation, but this won’t be a problem:

As you can see, `Process` doesn’t need to be changed despite SNLP having different iterators over the words. This is a desirable feature and one of the outcomes of the decoupling.
One other sign that you are progressing with decoupling is that you can start removing import statements. You only import a package to a class and not into the overall scripts. `Process` doesn’t need to “know” about either Spacy or SNLP.
Next Steps
Part 1 and Part 2 together gives an excellent headstart to think more consciously about choices in your codebase. With more practice, you will realize what works and what doesn’t, and you will be able to make these choices effortlesly and write good quality code from the start of the project. You will see how more efficient you became in solving problems which is the ultimate goal of maintaining good quality codebase.
Before I wrote the article, I asked the #production-code channel on the MLOps slack at: https://mlops-community.slack.com/ what patterns they use frequently, and they listed three more:
Bridge Pattern - to join data with model
Adapter Pattern - to do dependency inversion
Builder Pattern - to build complex classes
If you would like to know more about how these are used in a Data Science project, please leave a comment in the comment section, and I will write a blog on them in the series. Until then, happy coding and share/subscribe! Next part: “Code Smells”!
Szia Laszlo,
Hogy vagy? :) I take you up on your word at the end of this article. Would love to have the continuation of this article with how further design patterns are useful for data science.
Any chance on a follow-up article with Bridge Pattern - to join data with model, Adapter Pattern - to do dependency inversion, Builder Pattern - to build complex classes.
Koszonom, Timi
Hi Laszlo, thanks for the write up – it's easy to understand, and yet very illustrative of the advantages of the programming patterns.
Since Python treats functions as first-class citizens, I wonder what you think about using functions instead of classes in some scenarios, like the StanfordNLPLemmatizer, which is a class with just one method besides the __init__, and while it have state (self.pipeline), it's instance is never used more than once.
Classes have (hidden) state, that can lead to subtle bugs, whereas (pure) functions do not, so while a class is more extensible as the need for complexity grows, for these "simple" examples, I think a function could do just as nicely... but I would love to hear your perspective on that!
Best regards, Allan