
Refactoring BabyAGI - Code Quality and LLMs
Part 3 - Better service classes - 2023-05-05

[Edit]
The entire series:
Part 1: Code Review - planning the refactoring and identifying issues
Part 2: Clean Architecture - establishing the general structure
Part 3 (this): Better service classes and test doubles - decouple from external services and replace them with mocks.
Part 4: Preparing to introduce the Task class and first steps
Now that we are in a Clear Architecture and the structure is set, we can make actual refactoring decisions.
The TODO list from Part 2 [link]:
TestDoubles for OpenAI and PineCone
Move all openai calls to the openai_service class
Move all Pinecone calls to the pinecone_service class
General cleanup (inline, list comprehensions)
Calls to openai look like repeated code. Maybe this can be simplified?
Task class (this will be a really big one, so perhaps it will have its own blog post)
Let’s pass on the TestDoubles first and go for the more interesting next two steps. This is really not recommended; I only do it for educational reasons, but I _will_ write the TestDoubles later, I promise).
Refactoring LLM service
So let’s look at any time OpenAI is called. If you want to replace OpenAI with another LLM solution, you need a standardised interface. So any time BabyAGI calls OpenAI, it should happen through its “ai_service” member interface (class/object). OpenAI should implement this interface, and if you decide to use a new service, you wrap that with a class (this is the Adapter Pattern) and can easily be swapped.
Let’s take a look at one of these calls:

The other two are similar as well. The main steps are:
Construct the prompt from BabyAGIs parts, tasks, the entire tasklist or something else.
Call OpenAI
Deal with the return value
Construct the return value and return
The OpenAI call has a lot of parameters that are very similar to this. Let’s start with that. First, merge points 2 and 3, as these always happen together. But there is a problem:

This last one doesn’t have “split(‘\n’)” at the end. Move this on the other two occasions to the place where the return value is used:

Now OpenAI is called the same way on all three occasions. Let’s extract this part while looking at the change in the parameters. Use the typical values as defaults:
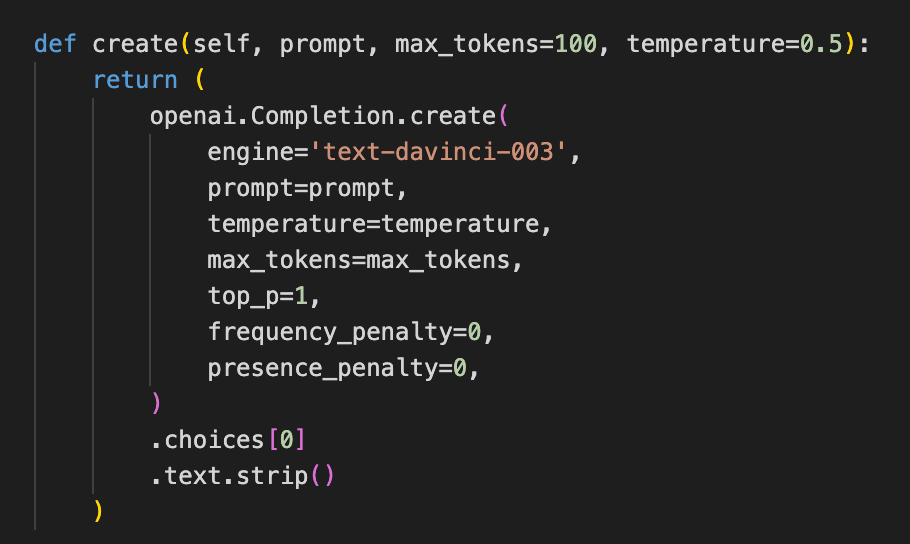
And the three callers:

In task_creation_agent, the call can be inlined. In the priortization_agent, the processing of results doesn’t look Pythonic. This can be factored in as well. The execution_agent is just two lines; this may be inlined and removed altogether. I wrote TODOs for these to remind myself.
But first, let’s look at the vector service.
Refactoring Pinecone calls
Any time the “index” is used, this should happen through the “self.vector_service” member variable. Let’s take a look at the context_agent:

Context agent returns a list of strings sorted. Of course, it would be better if it returned some relevant classes (namely “Tasks”), but that should be a later step.
So this will look like this:

And the caller:

As you can see, both of these are really short, and context_agent is only used once in execution_agent. So I make a note to inline this.
Often it is a good strategy to inline until you inline too much and then undo some. Inlining allows you to review the structure of your code and avoid unnecessary naming. The fewer names you need to make, the better. I often see creating a variable and then immediately returning it. This is almost always extra code with an extra name. Simplify if possible.
But first, deal with the other call to the vector DB:

This looks pretty straightforward (Or is it? More on this later). Just move the code to the vector service.
And we are done with the service refactoring. The main code is independent of the two external services through the “Adapter Design Pattern”. We can replace them with test doubles and run the code as often as we want while doing the refactoring cycles.
Test Doubles
OpenAI
Let’s write these classes as well. For OpenAI, I will write a class that will cache the responses for each prompt. If a prompt is in the cache, it returns the value, but if it is not, it will call OpenAI for a result, put it in a cache and save the cache.
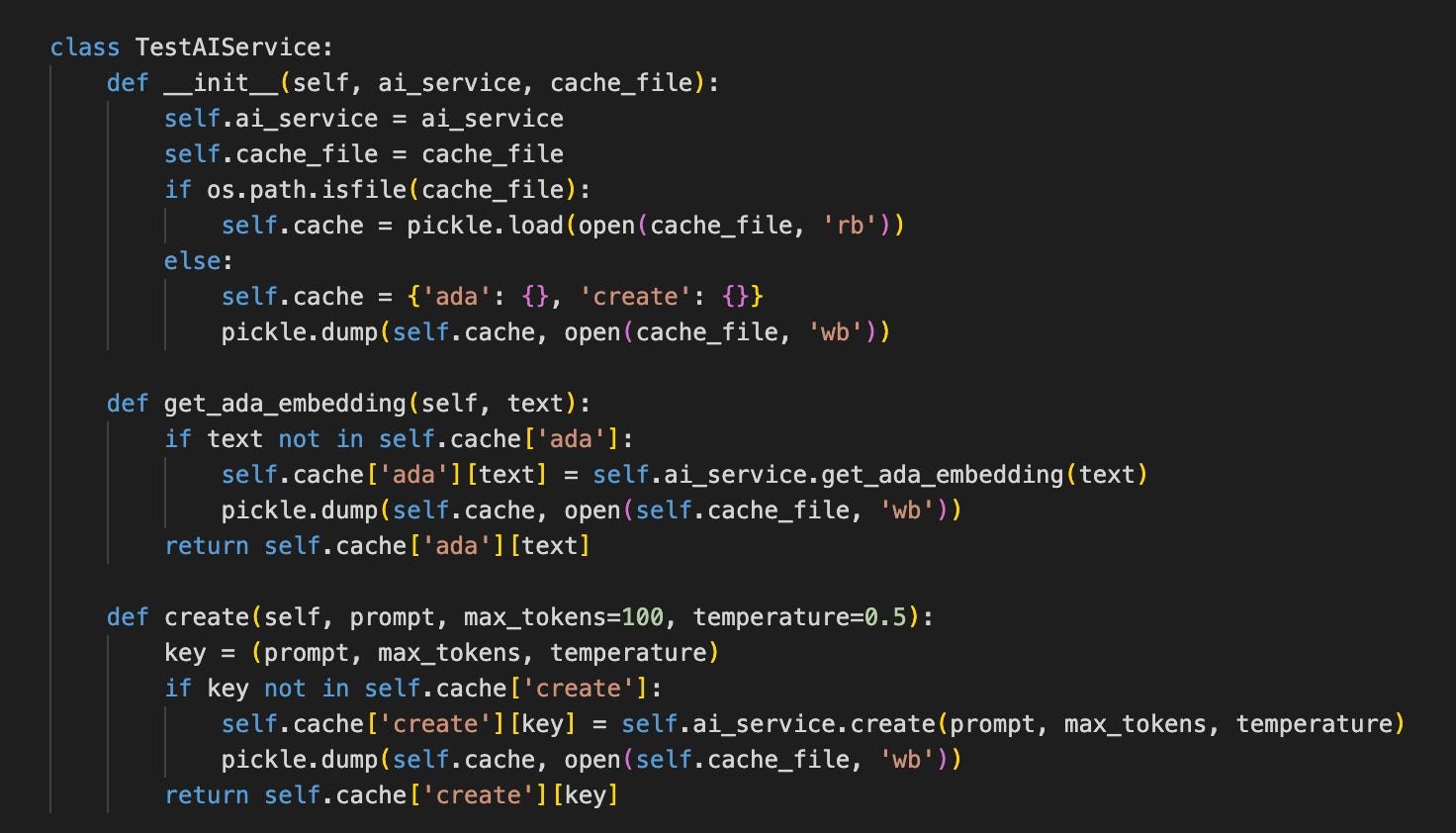
This has the same interface as “OpenAIService”, so it can be plugged into its place, and BabyAGI doesn’t know that it is not connected to the real service, just a cache. This allows the tests to run much faster and cheaper.
Pinecone
To replace Pinecone with something faster, I decided to use LanceDB. This is definitely not a “boring” technology, but the learning experience is part of the journey, so I decided to figure it out with one go:
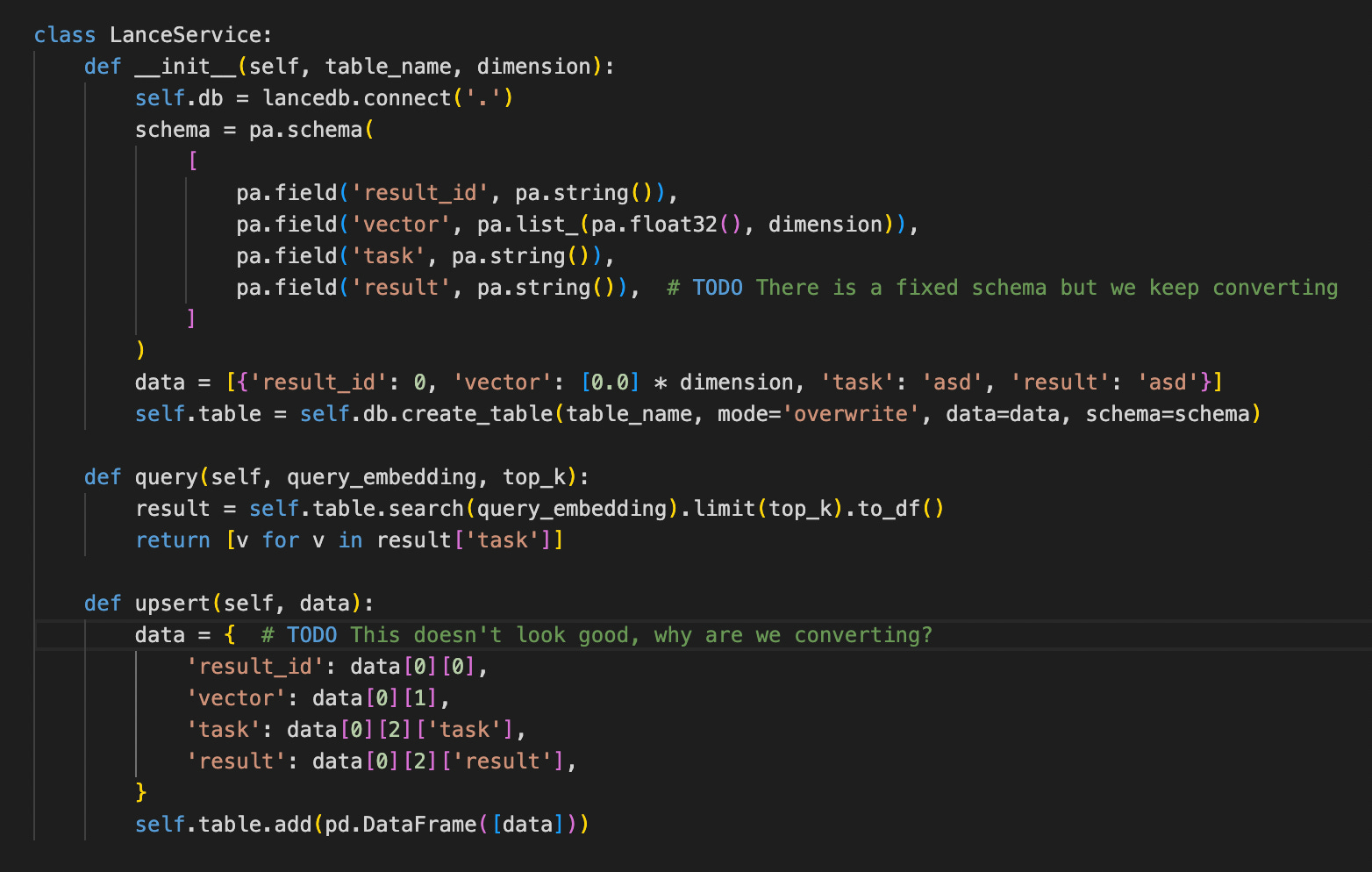
So there are a couple of points here. The interface is exactly the same as PineconeService’s. For a different use case, I would stick to something simpler, but mocking vector databases is not easy. I hope Lance will do the job because this can be a good solution—similar to SQLite for “real” databases.
There are already a couple of TODOs. Passing the data around is really weird. A lot of conversions. This comes from the “Primitive Obsession” smell I mentioned in Part 2. For a codebase like this, everything should be about tasks and Task classes. That will definitely be a future step.
New Setup
This is what the new setup looks like (I left the old PineconeService declaration commented out for reference):

As expected, if you run it for the first time (after deleting the OpenAI cache file), it runs pretty slowly. But the next time, it is blazing fast. So now you can move the code around as you please and see if it still runs.
I also recognised a new problem: OpenAI sets the size of the embeddings internally (to 3x512) then we define the vector databases dimensions independently. But these must match.
One idea is to instantiate the AI service first and then call some property function that would return this information and set the Vector DB’s dimension based on that.
I leave it for now because it is not too much of a problem, but you need to fix it long-term.
Summary
So far, the TODO list was:
TestDoubles for OpenAI and PineConeMove all openai calls to the openai_service classMove all Pinecone calls to the pinecone_service classGeneral cleanup (inline, list comprehensions)
Calls to openai look like repeated code. Maybe this can be simplified?Task class (this will be a really big one, so perhaps it will have its own blog post)
Dimension dependency between AI service and Vector DB
So in Part 3, the two services are properly decoupled and replaced with TestDoubles so you can have a very fast iteration.
Part 4 will be general cleanup and then introducing the Task class. Subscribe if you would like to be notified:
[Edit]
The entire series:
Part 1: Code Review - planning the refactoring and identifying issues
Part 2: Clean Architecture - establishing the general structure
Part 3 (this): Better service classes and test doubles - decouple from external services and replace them with mocks.
Part 4: Preparing to introduce the Task class and first steps