
Refactoring BabyAGI - Code Quality and LLMs
Part 1 - Code Review - 2023-04-28

BabyAGI is an early implementation of autonomous agents based on LLMs. When I realised that the core code base is only 140 lines, I thought this could be a good exercise to refactor it along with the Clean Architecture principles we utilise in other projects.
My goals are:
Learn more about services around LLMs. (here, OpenAI and Pinecone)
Practice refactoring with hard-to-test external services (Openai)
Does it work at all? (We will see)
Learning opportunity (for the readers and me)
The refactoring exercise is not a comment on its current quality or the original authors (I have no affiliation with them, BTW), just an application of our guidelines.
Refactoring and tech debt removal need a reason, which is usually a request for new features that are somehow blocked by the current state of the codebase. This kind of exercise is usually practised on much larger and faster-moving codebases.
I am also not sure about the direction. If you disagree with some of the choices, please let me know. One of the good things about refactorable codebases is that new ideas are relatively easy to incorporate.
In the end, this is primarily a learning exercise and documentation of a thought process.
Throughout the series, I will use the “Classic” version [link]. I removed comments, print statements and the original prompts to make the code a bit more compact, but these shouldn’t affect the process anyway.
[Edit]
The entire series:
Part 1 (this): Code Review - planning the refactoring and identifying issues
Part 2: Clean Architecture - establishing the general structure
Part 3: Better service classes and test doubles - decouple from external services and replace them with mocks.
Part 4: Preparing to introduce the Task class and first steps
What am I looking at first?
When looking at a legacy codebase, it is almost impossible to comprehend the entire content at once. This isn't easy even in this codebase which is only ~140 lines.
Find the main entry point. Where does the execution start? Keep following the main branch and try to understand what is happening.
At the same time, follow the variables you learn about: Where are they declared, where are they initialised, and where else are they used apart from where you just read it?
Look out for the following:
Scrolling up and down a lot is a sign of “Improper scope”. A variable should be used close to where it is declared and forgotten as soon as possible (there are exceptions, of course, but you get a general idea)
Declutter: Remove anything that is not strictly needed: Unused variables, comments (after reading them), or dead code.
Simple changes: inline variables if you can, refactor loops into comprehensions, naming variables is a difficult task, so the best if you don’t have to do it at all.
Try mapping a basic structure: Having a rough end goal is a good idea. It’s like a plan that didn’t come into contact with reality yet. Here it will look like the following:
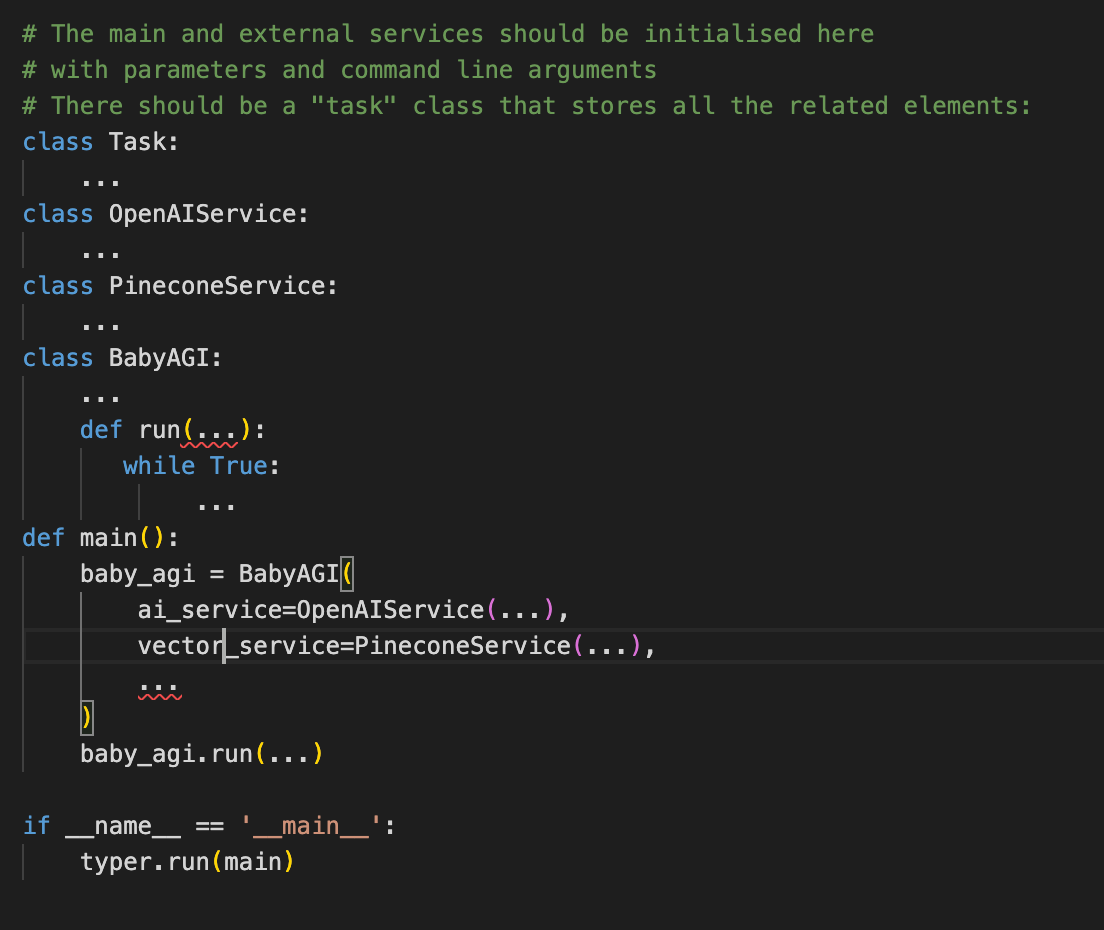
This is a typical “Clean Architecture” structure we use in our projects. The entire program is one class with a “run()” function, which contains most of the work.
Any external dependency is plugged in as a class, these will contain their configuration, so you don’t need to have that scattered around in the code.
The “main()” function will also call the “run()” function, which is a very simple “Inversion of Control” solution. If we need to ship this into a more convoluted environment, that environment can just call the “run()” entry point and everything will run as if it was on your machine.
For testing, the external services can be replaced by “test doubles”, classes that have the same interface as the real ones and simulate their behaviour for test cases but don’t connect to the real service—no need for mocking with these.
The entire thing is wrapped with Typer, so we don’t need to worry about CLI interfaces. “It just works”. If you want to pass some quick and dirty parameters during refactoring to the program, you can do it here easily.
First section: Configuration

The first section is mainly concerned with imports, parameters and constants. The two major import statements (openai and pinecone) indicate external dependencies; it is worth taking notes that, most likely, these need to be wrapped with the Adapter Pattern and plugged into the main class through them so that in testing, they can be replaced by a Test Double.
Hardcoding the constants is a problem as they are difficult to change and are used all over the codebase. It would be better to have them only in one place, and you only use a reference everywhere else. Or don’t use them at all… We will see later how the plans above will allow us to do that.
Second section: Proto BabyAGI service

This is certainly important. Autonomous agents execute tasks and maintain a list of tasks to be executed. It would be great if these would be made explicit, and there would be a “Task” class and a dedicated service, “BabyAGI”, that manages it. This is called “ubiquitous language”, where terminology from the domain and problem you want to solve appear explicitly in the code. So when you are talking about and explaining (potentially to a non-tech SME) the workings of your code, you don’t need to translate your terminology.
Third section: OpenAI calls
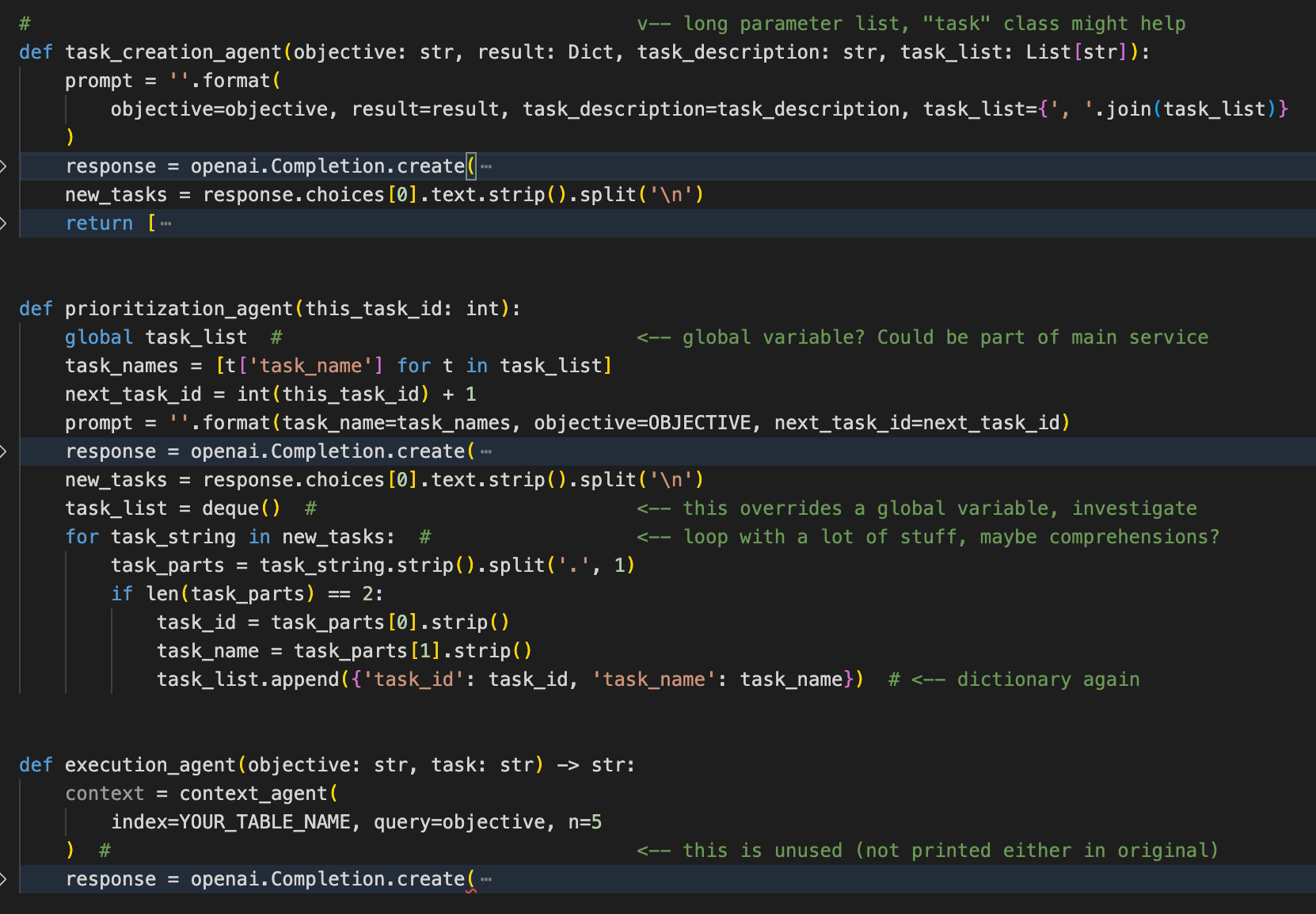
The following section is mainly concerned with calling OpenAI and managing the tasks (in dictionary form) and task lists. Ultimately LLMs accept and return pure text, so processing the output is always messy, but this is made a bit harder here by not having a consistent structure for the tasks (the “Task” class).
I collapsed the responses because they look very similar, which indicates there might be some common pattern to be extracted.
The only strange thing is that declaration of “task_list”. I am not sure what to do about that. This is certainly something you need to be aware of as you progress.
Fourth section: Pinecone calls

This is the only place where pinecone is used, so it is probably a good idea to move it into a service where it can be connected to the configuration and construction.
Fifth section: Main body
And we are at the main body of the script:

I left some comments here because they are typical of why comments are usually useless.
It says “Add the first task”, then has a variable called “first_task”, and then a function called “add_task(first_task)”. What else do you think this part of the code does other than “Add the first task”???
Well, unless there is an excellent reason, remove all comments. Focus on writing more readable code. This, of course, doesn’t apply to packages which are used by many where the docs act as a reminder for what this or that function does.
The main section is pretty straightforward. Calls the various “agents” that are actually functions in a row and maintains the task list. The code is pretty difficult to read because the task is not a class but a dictionary, and all kinds of string-based access are required to maintain the data flow. This asks for a dataclass.
Summary and next steps
And that’s it. It is just 140 rows, so the above exercise can be done quickly if you don’t need to blog simultaneously. For larger codebases, you need to spend more time reading and understanding, but that’s still a relatively short period, and then you can get on with refactoring.
To make it so, you should write a proper test setup first to make subsequent changes fast and verify that they didn’t break anything. The plan is the following:
Extract external dependencies into their own class
Move all other code into the BabyAGI class
Test if it is running
Replace external dependencies with TestDoubles
Introduce the “Task” class
Refactor everything to use “Task” classes
General readability and code quality changes (while running the tests)
If you like this and want to be notified of the following parts, subscribe here:
[Edit]
The entire series:
Part 1 (this): Code Review - planning the refactoring and identifying issues
Part 2: Clean Architecture - establishing the general structure
Part 3: Better service classes and test doubles - decouple from external services and replace them with mocks.
Part 4: Preparing to introduce the Task class and first steps
If you would like to read more on the topic:
Clean Architecture (slides and video):
Refactoring another project (with exercises):
More on Clean Architecture:
Thank you for the excellent series! It would be also very helpful if links to all other posts in the series were provided here. Thanks!