
Refactoring BabyAGI - Code Quality and LLMs
Part 4 - Task class - 2023-05-06

This is the fourth part of the Refactoring BabyAGI series.
[Edit]
The entire series:
Part 1: Code Review - planning the refactoring and identifying issues
Part 2: Clean Architecture - establishing the general structure
Part 3: Better service classes and test doubles - decouple from external services and replace them with mocks.
Part 4 (this): Preparing to introduce the Task class and first steps
The remaining TODOs:
General cleanup (inline, list comprehensions)
Task class (this will be a really big one, so perhaps it will have its own blog post)
Dimension dependency between AI service and Vector DB
Before we introduce the Task class, which is pretty much the last major step before we can move on and review what else should be done, we should prepare first.
The problem with dealing with legacy codebase is that extracting relevant domain items is obvious but hard to execute. The tasks are entangled everywhere along the lines of the current implementation, so before we start breaking it out, we better help ourselves.
This will be achieved by rewriting some parts to be more Pythonic. Inline whatever doesn’t affect readability. We can always undo it later if it is better that way.
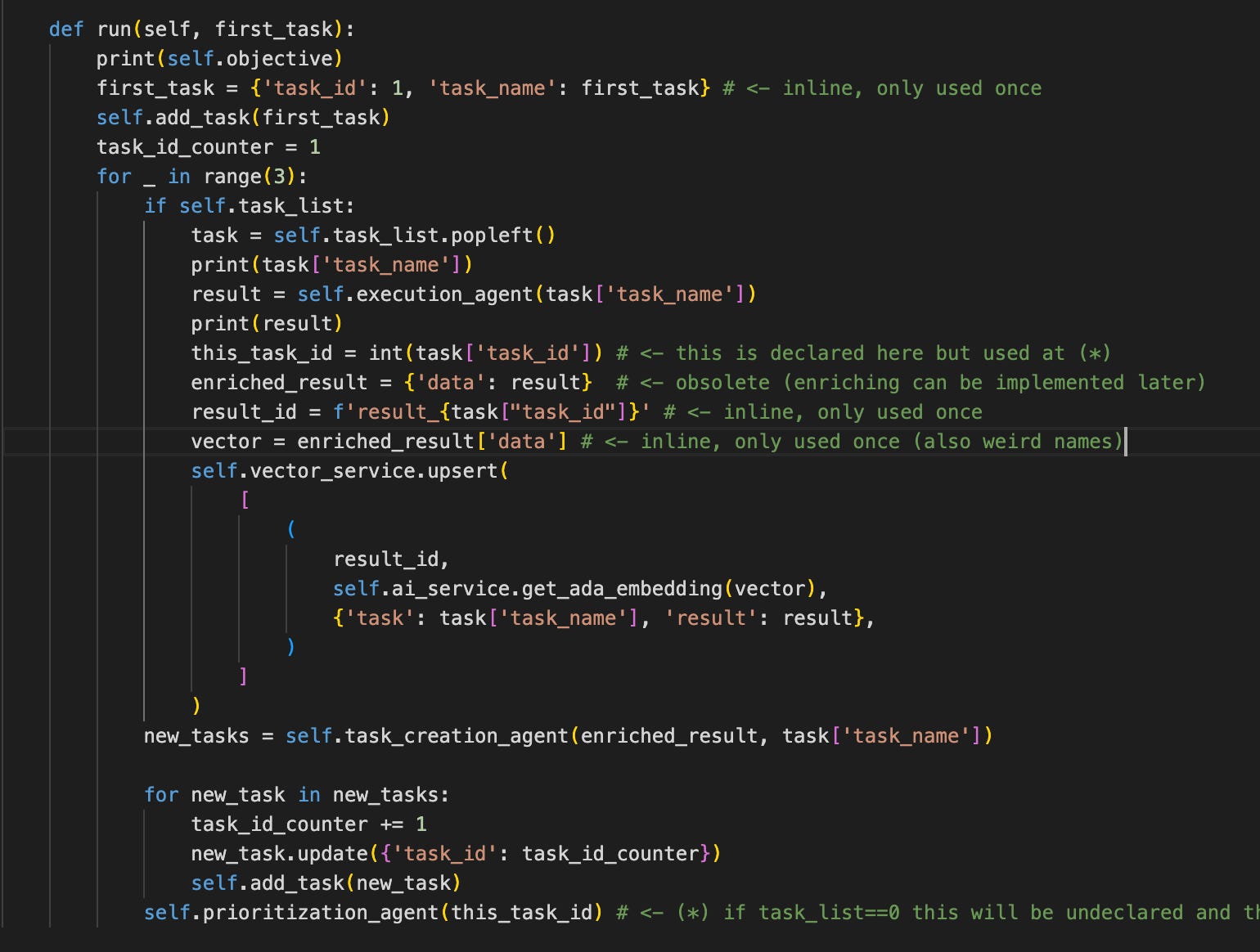
Let’s take a look at run() first:
After:

A lot of things were inlined so we could see where the Task classes would fit in. There is definitely something weird going on with the task_id-s. These need to be sorted out later.
I also removed the references to “enrichment”. This is a feature request. It’s easy to put it back if it will be needed in the future; until then, it is YAGNI.
Let’s inline execution_agent and context_agent in case something interesting comes out of it:
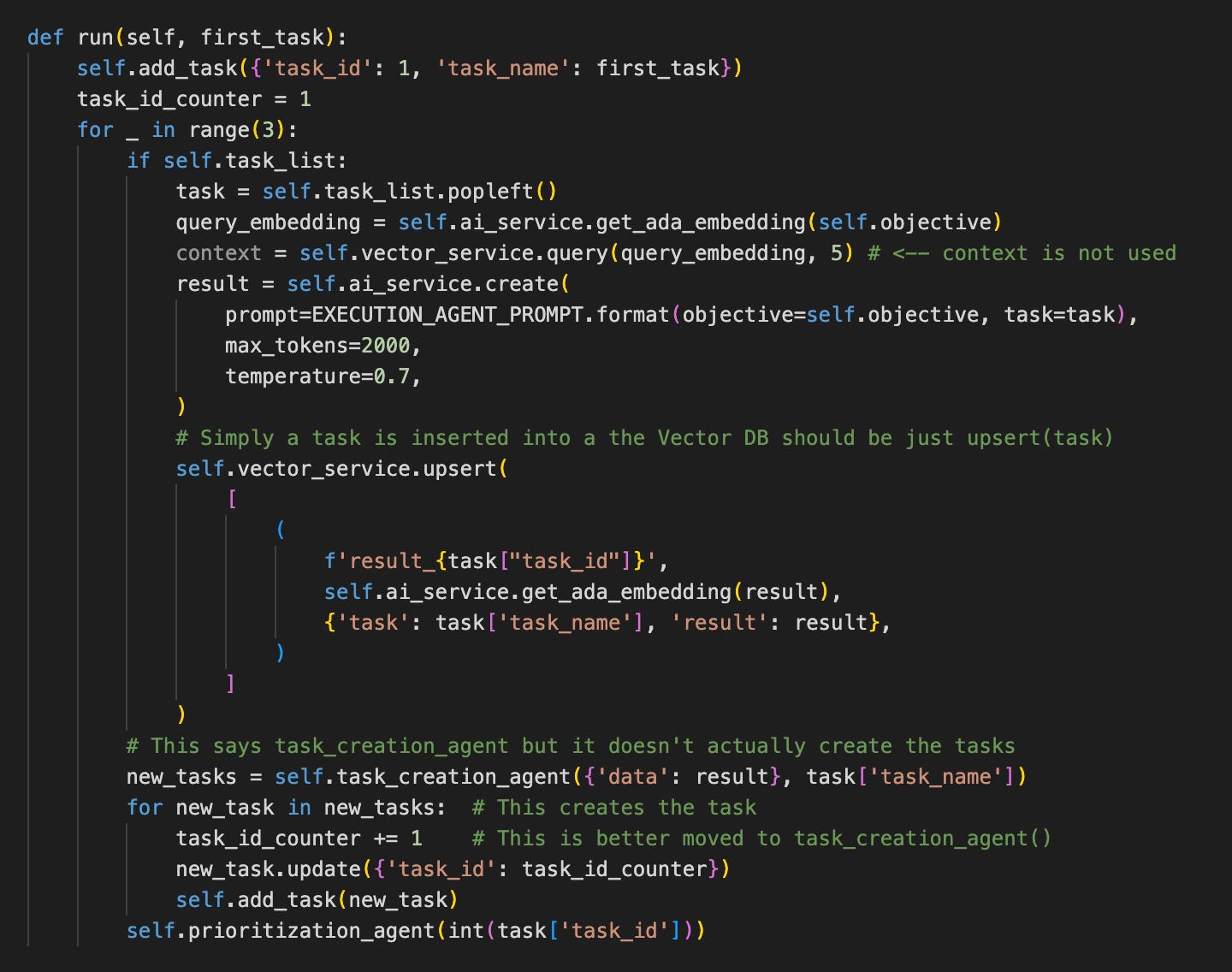
This might need to change, but for now, it will do. We will see when we have the task class if it is readable.
The task_creation_agent, instead of creating the tasks itself, passes back the results. We should move that loop to that function.
It looks like this now, and the commented-out section needs to be inserted.

Take note of task_id_counter. This counts how many tasks were ever created. This is a property of BabyAGI, so we should add it to it, and then we don’t need to pass it around as arguments. Also, add_task() is the only place where this can be incremented, so we should have that handled there. This doesn’t make this right because it is unclear where the IDs are coming from, but it will do for now.
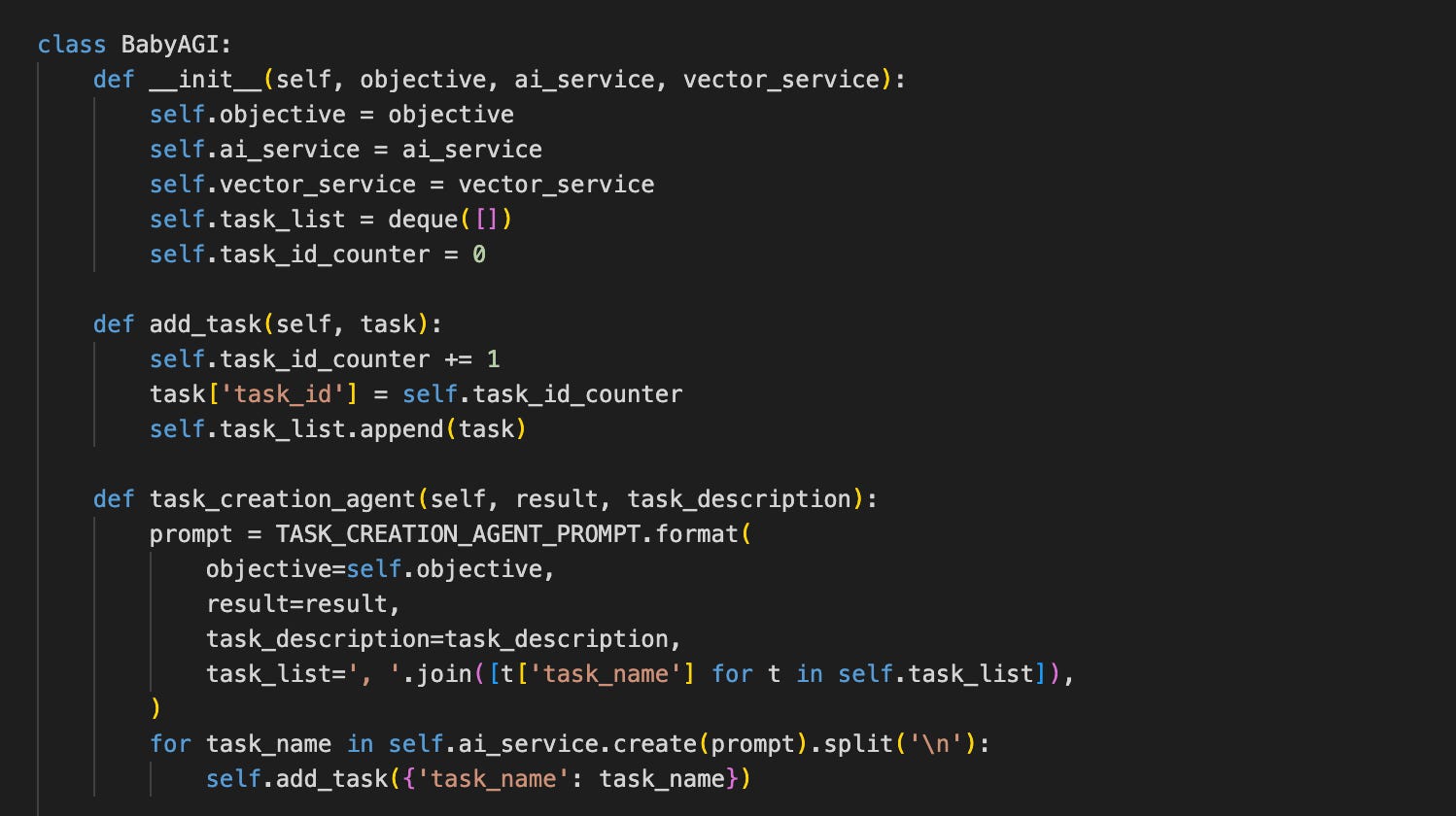
I also copied the rest of BabyAGI to see how it turned out. We deal with the id in add_task and simplify the code in task_creation_agent to a single line.
Let’s take a look at next the prioritization_agent:
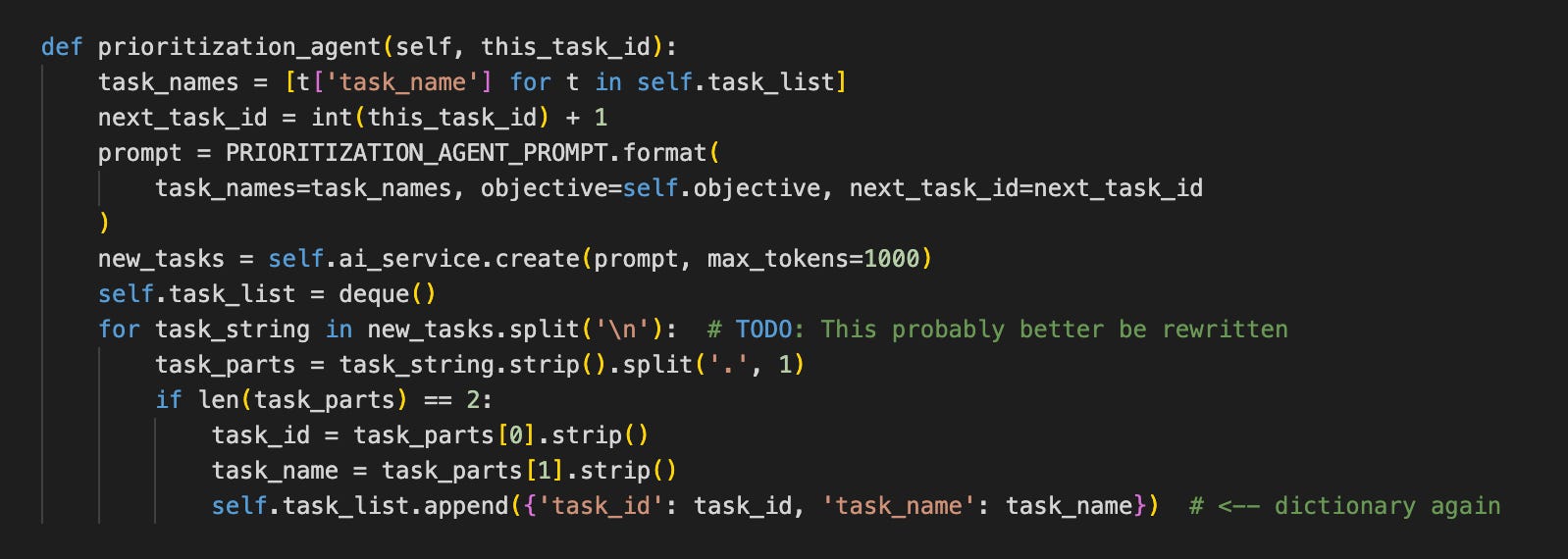
The problem is that we manage the task_ids through add_task, but this function doesn’t call add_task, just append directly. We should refactor this to use add_task.
One step backward, two steps forward
Also, there is a weird hackery with the IDs. Suppose I understand from the prompts. The agent asks ChatGPT to number the prioritised tasks from the id of the last executed task (the current top priority one).
This means when the new task_creation_agent creates new tasks, it will have incorrect IDs. A better solution for this is that in add_task, we don’t use a counter, but if we see a task without ID, we will set it to +1, the highest ID in the queue.
So we should rewrite the add_task function that we just wrote. This is pretty typical of dealing with legacy code. You have no chance of understanding it in its entirety, so you will recognise these issues as you go along. You can only plan for these so much.
This is why testability and version control are so important because, at any point, you want to go back and forth quickly, try new ideas, and not worry if it breaks the code. Or if it does, be notified about it as soon as possible.

So now it looks like this. Note the new add_task function. Of course, there was a bug here that didn’t come up so far. In the last line, task_id is a result of a split, so it is a string, yet all other task_ids are integers. So you need to convert it into one.
So let’s take a look at that prioritisation and task list creation again at the bottom:
The response to the prompt is a list of tasks numbered as requested. First, it is split. Then split again on “.” (dot). If the result has two parts (the number and the task), we form a new task and add it to the list.
This can be done with just two comprehensions. One creates the pairs, and another creates the list.

We don’t need to worry about the add_task for now because these tasks all have IDs. But this doesn’t look good in general—too much string manipulation. Let’s try a helper function.
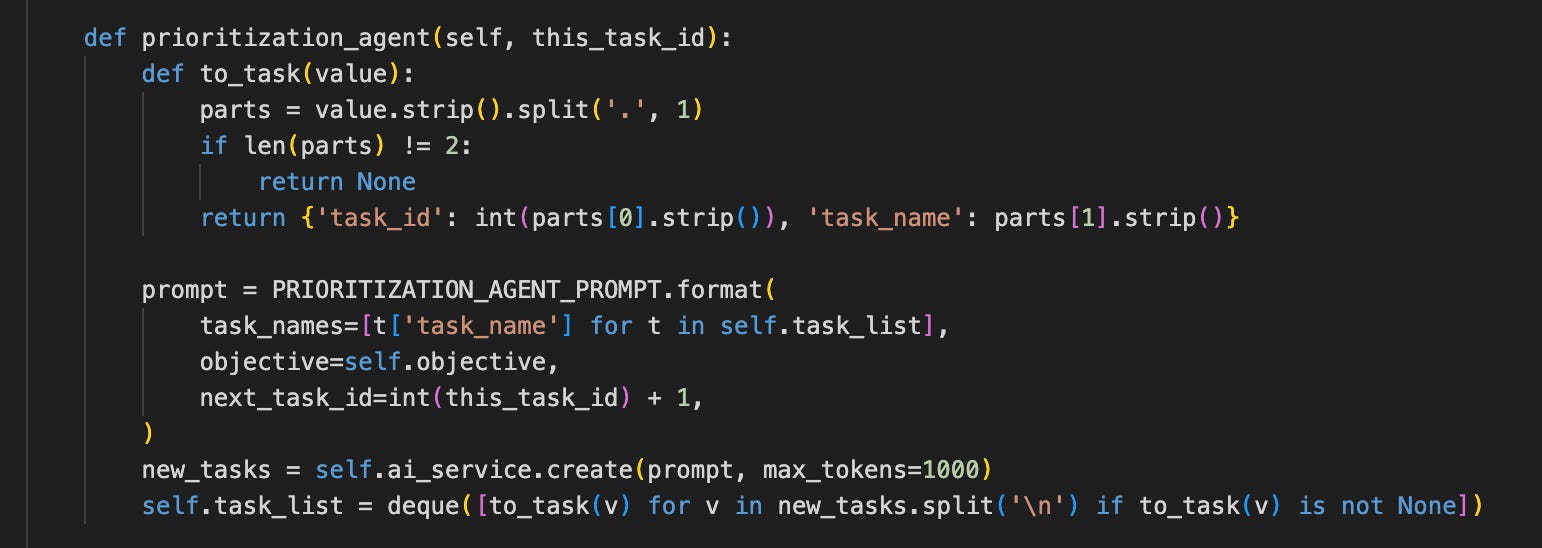
So this looks better. The details of how to turn a piece of string into a task are extracted into a function. It is not great with the “None” filtering and running the function twice on each function, but it will do for now. This can be solved with generators and yield, but it is probably overkill here.
One small change in the context agent each time it is called calculates the embedding for the objective. This is clearly a waste; we can just cache it in the constructor.

Then it looks like this:

One less service call.
Task class
Time to introduce the task class. It is pretty easy to define as the parts are already known.

We allow default None values and handle these at different times. There might be some rationale for having two of these: a Task and a Result, but now we will do it in one. This is the typical question that time will decide, and the next refactoring iteration, when you know more about what you want, will decide.
Essentially next step we need to go over any place where part of a task is accessed and replace it with the class and property access.

Immediately both the adding the first task and the add_task() functions need to change.
This post is already too long, so I will finish it in a new one.
[Edit]
The entire series:
Part 1: Code Review - planning the refactoring and identifying issues
Part 2: Clean Architecture - establishing the general structure
Part 3: Better service classes and test doubles - decouple from external services and replace them with mocks.
Part 4 (this): Preparing to introduce the Task class and first steps
Subscribe to be notified: