
Refactoring BabyAGI - Code Quality and LLMs
Part 2 - Service classes

This is the second part of the Refactoring BabyAGI service. The original code is just 140 lines which makes it ideal for this exercise to demonstrate how to combine Clean Architecture and basic Design Patterns (mainly the Adapter Pattern) and domain data modelling with LLM-based code.
[Edit]
The entire series:
Part 1: Code Review - planning the refactoring and identifying issues
Part 2 (this): Clean Architecture - establishing the general structure
Part 3: Better service classes and test doubles - decouple from external services and replace them with mocks.
Part 4: Preparing to introduce the Task class and first steps
In the first part [link], we reviewed the codebase and identified the basic structure and some TODOs, so here we will execute the following steps:
Write service classes
Move existing code into these classes
Set up the main function, instantiate these classes, and plug these into the main (BabyAGI) service class.
Inline constants and parameters so they are closer to their use. This will make dealing with config and serialisation/deserialisation easier later.
Later steps:
Write Task class and refactor wherever task-related activities happen
General readability
Config and serialisation
It’s important to move the code to a nicer format before you engage with the heavier steps is important because you can easily get lost.
I also have problems with the free PineconeDB account, so that I might switch to a different one. Maybe that’s worth its own part. At some point, you need to set up a test loop so you can refactor safely (change the code syntactically and verify that it is still doing what it was doing before).

This is the basic structure that we are aiming for. It uses Typer, so we don’t need to worry about any CLI problems.
The main body of the code will be moved to a single class (BabyAGI) which connects to external dependencies through other classes (Adapter Design Pattern) but itself not dependent on this. OpenAI is expensive, and if you want to run the code a lot in testing, you need to replace it with a “TestDouble” that fakes the real service faster and for free. More on this later.
It implements “Inversion of Control”. After the BabyAGI class is instantiated, the “main()” function calls its “run()” entry point. IOC isolates the code from the environment it is running in. Inside the BabyAGI class (the most interesting part of the code), there will be no irrelevant details, just code about managing tasks.
Step 1: Service classes
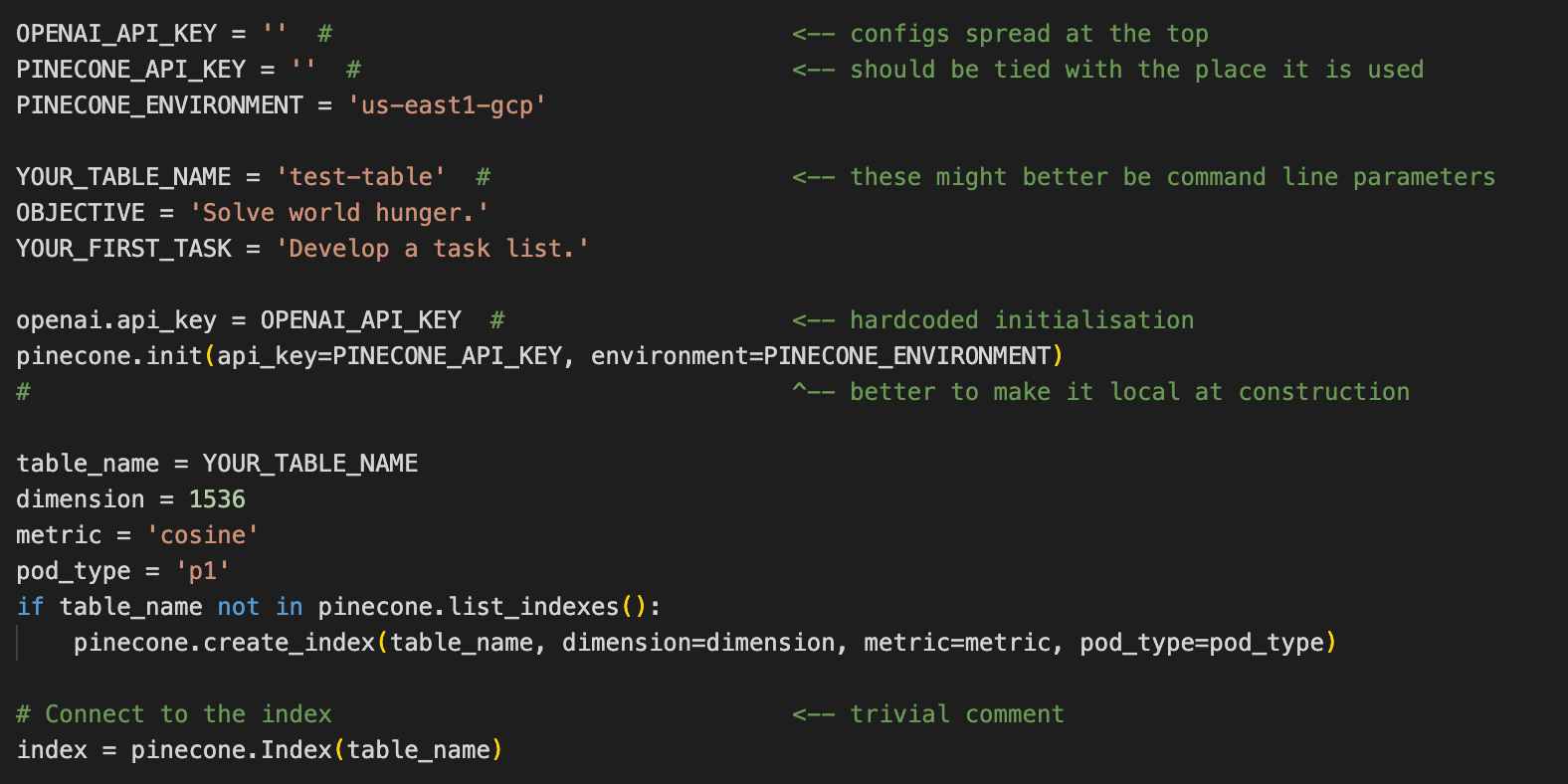
This part is a bunch of parameters and variables for OpenAI and PineCone. Let’s create a class and inline these constants. We can decide what to do with them later.
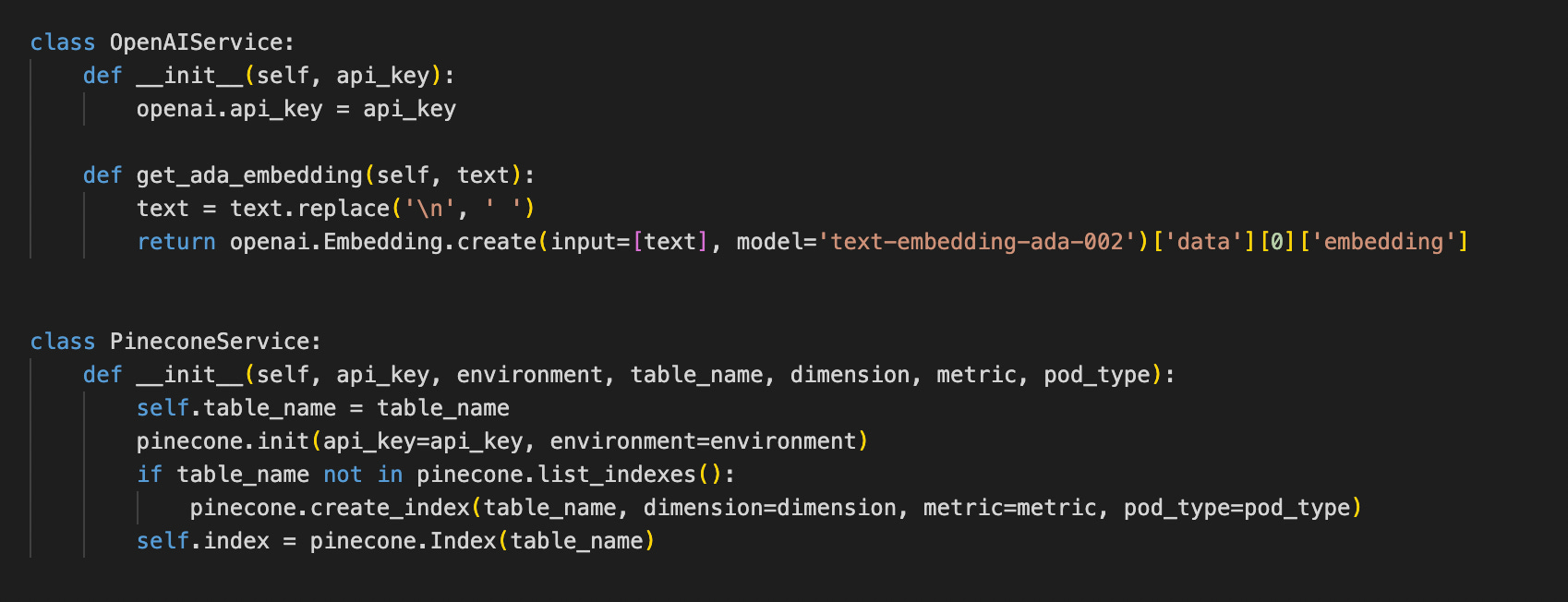
The classes look like this, nothing fancy, just moving the code. Let’s look at next the BabyAGI class. Before, it looked like this (Note that I moved the OBJECTIVE and YOUR_FIRST_TASK constants here so it looks better on the screenshot, but these were mixed above with the service parameters):

These clearly belong to the main class:

So here you can see that the class “knows” about two abstract services (ai and vector) currently implemented through OpenAI and Pinecone but doesn’t need to be like this.
And here is the final setup:

As you can see, it uses the dotenv library’s “load_dotenv()” function to set the keys which are in a “.env” file. These shouldn’t be in the code or a repo, so “.env” is in “.gitignore‘ as well. Good to sort this out early before you expose something secret. Takes about 2 minutes.
It’s questionable if the “objective” should be part of the class. It is used all over the place and doesn’t change through the lifecycle of the class, so I added it to the constructor, but this doesn’t have to be. The point of refactoring is that you can change it later.
This would be the end, but the code must run as well. So we need to go through the entire codebase and fix the errors due to the changes above.
Step 2: Fixes
Original:
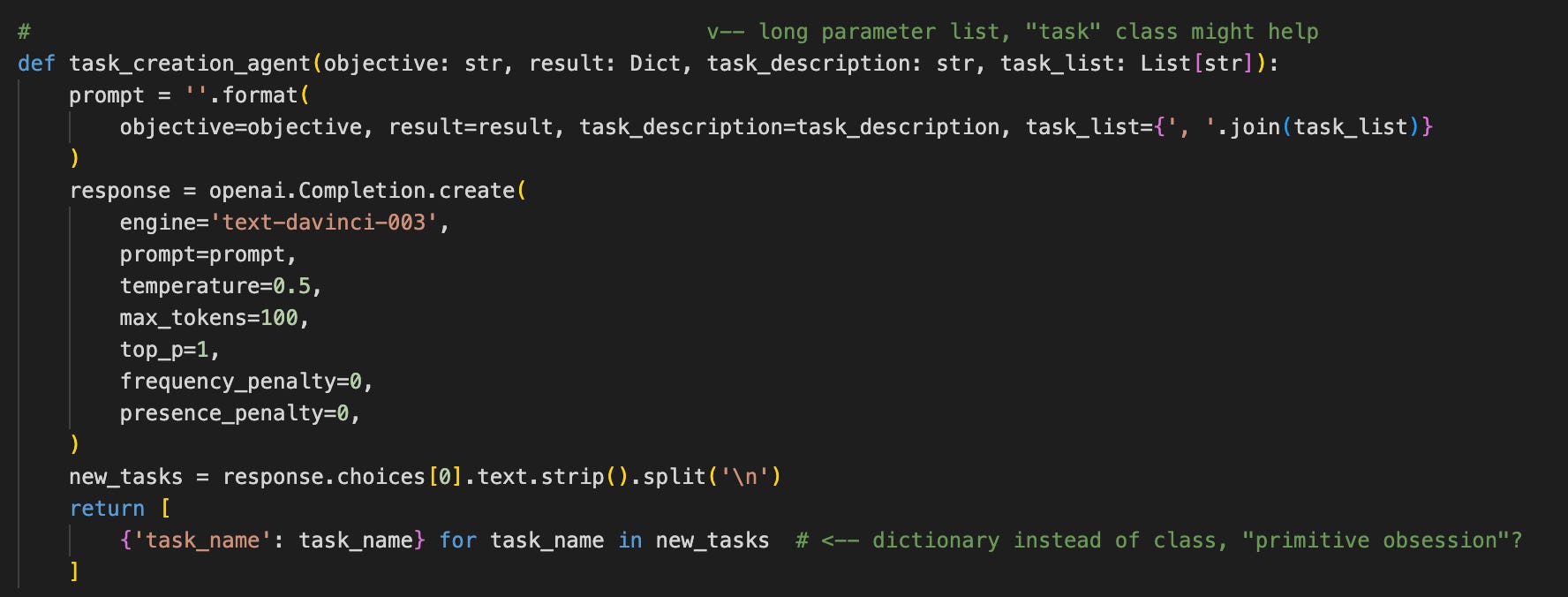
Modified:

First, the parameter list: Because objective and task_list are part of the class, they don’t need to be passed explicitly.
As you can see, the function still calls openai directly and not through self.ai_service This will be a TODO to fix for the next step.
It looks like there is nothing else going on here. The code looks different because “black” automatically standardised it. Highly recommended.
The next is the prioritisation agent. Before:

After:
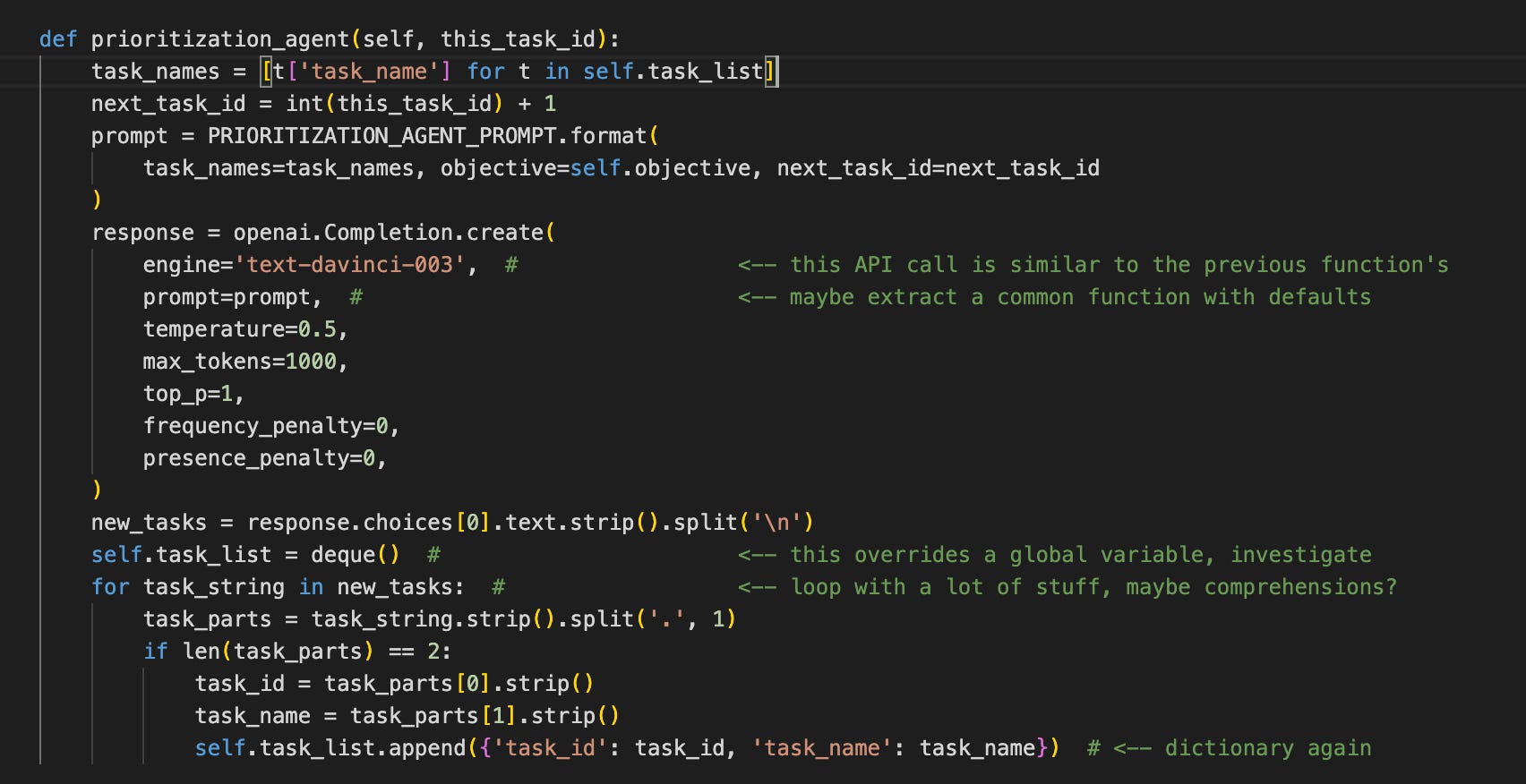
Objective and task_list are member variables, so they should be switched from global to indicate that.
The next is the execution_agent and context_agent. Before:
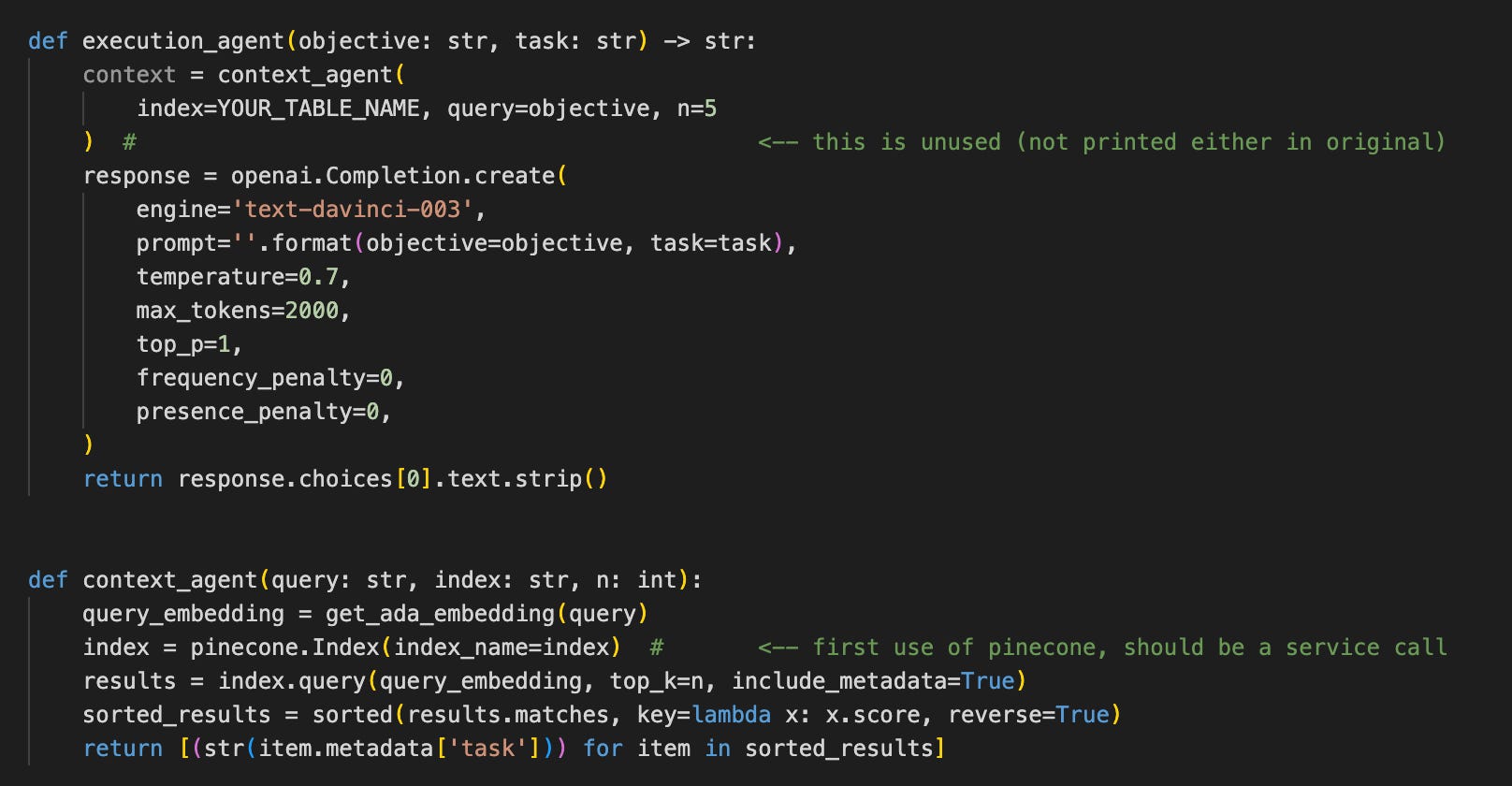
After:

Execution_agent calls context_agent and then openai again. The only job of context_agent is to do a search. Maybe this should be part of the vector_service and context_agent inlined into execution_agent. We will see it in the next part.
Also, weirdly the “context” variable is never actually used (hence its grey colour in the IDE). This might be an error or a missing part in the original, but I kept it for educational purposes. Usually, dead code should be deleted with inaccessible code and trivial comments. The less text, the better.
Feature Envy
Note that context_agent accesses the vector_service’s “index” field and calls query() directly. This is a code smell called “Feature Envy”. Context_agnet (and, in turn, BabyAGI is concerned with detail (the fact that the vector_service) has an “index” field that it shouldn’t be. The only reason this is happening is because we know that Pinecone has this field. If we want to use a different vector DB either that should have an index field, or we should rewrite this part of the code. But then it won’t work with Pinecone any more.
This should be refactored, and BabyAGI and context_agent should call the vector_service’s query() function, and it should be implementing this however it pleases. Decoupling FTW.
Main function
Before:
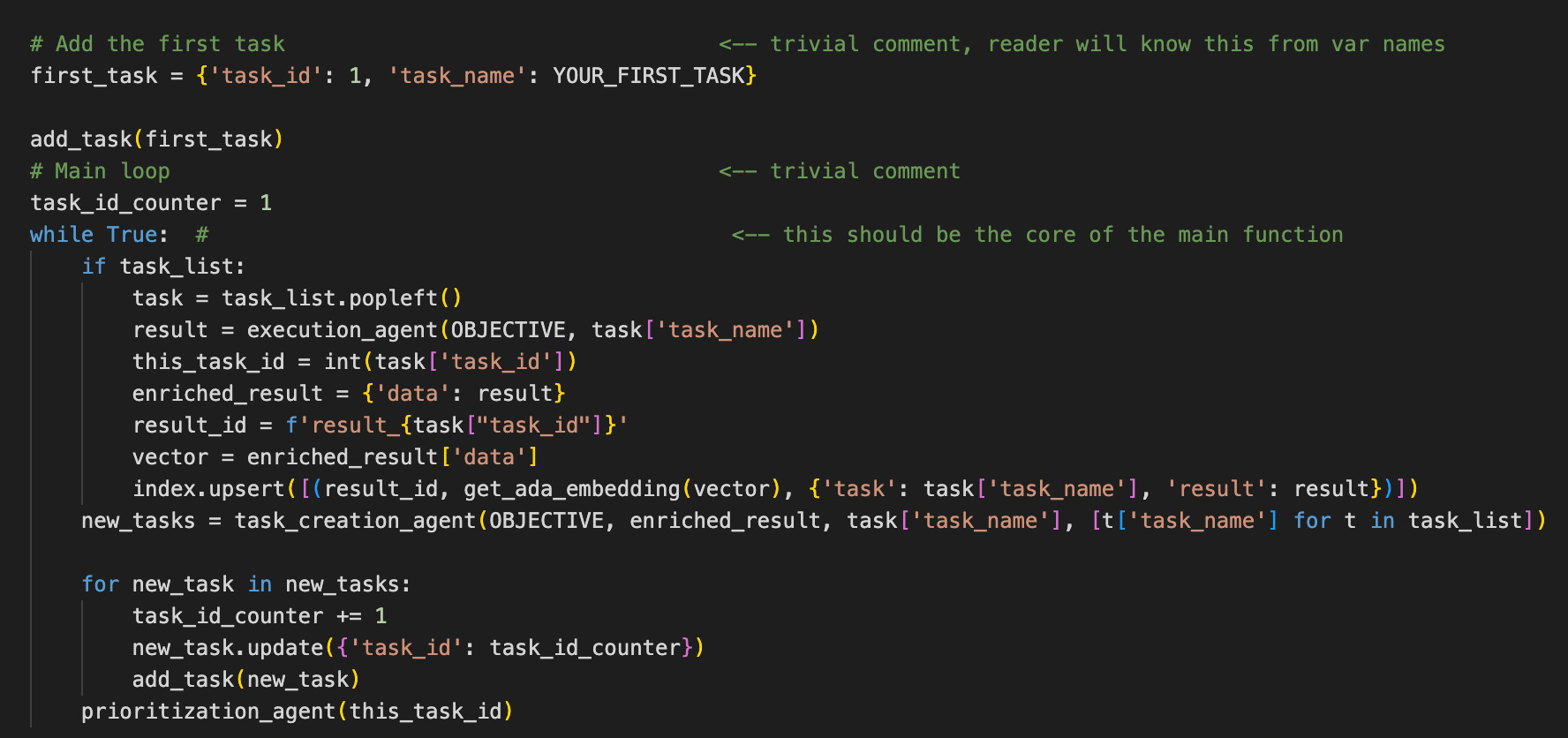
After:
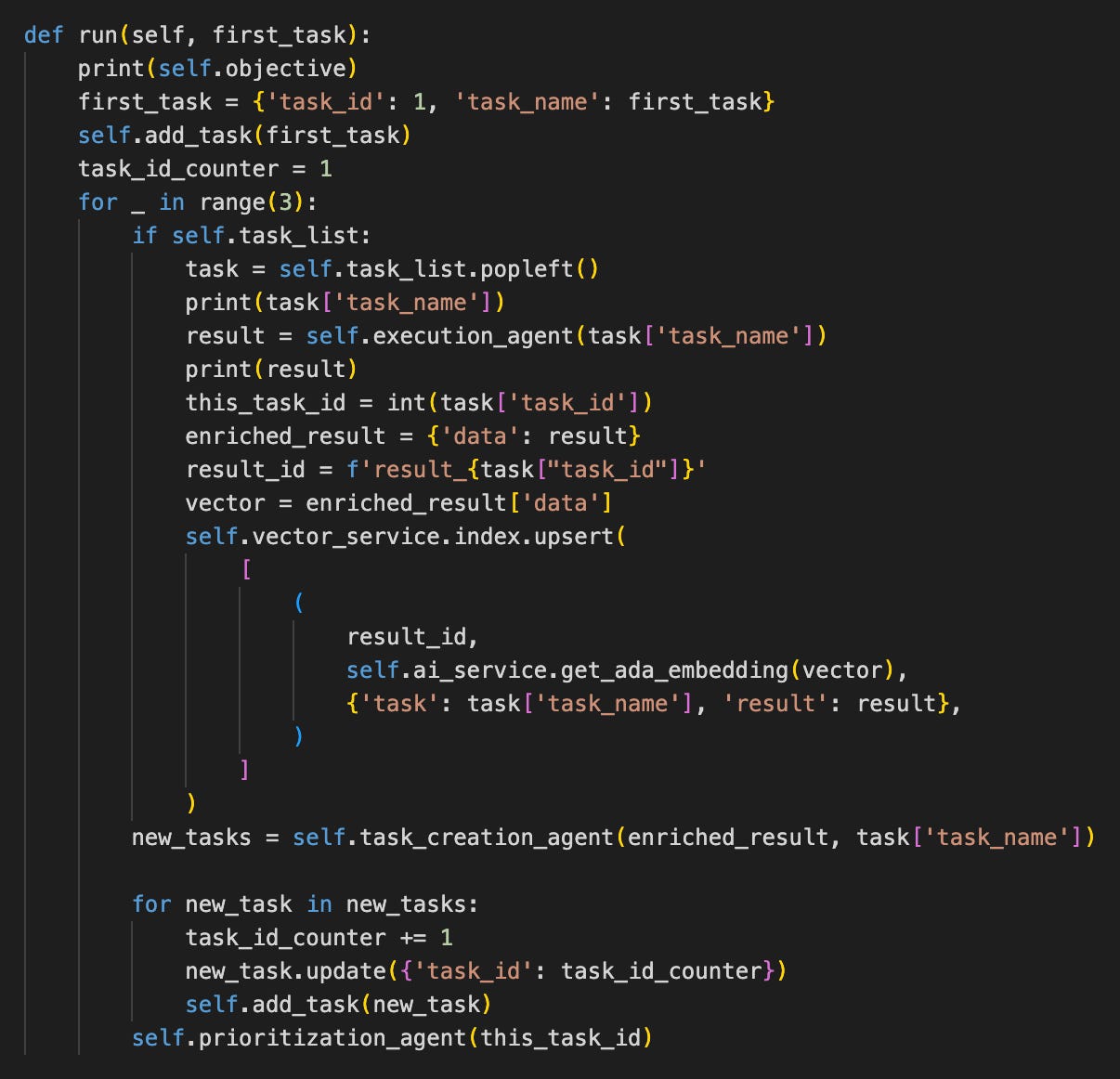
Here we need to take care of all the member variables and functions by adding “self.” before them. I also switched from an infinite loop to a shorter one so we don’t use up all our OpenAI credits.
We can also remove the parameters that refer to a member variable in the class because these can be accessed directly in those functions (objective, task_list).
Primitive Obsession
Note the number of dictionary accesses (pretty much all the strings in the second image). These are signs of a code smell called “Primitive Obsession”. Instead of using a well-defined domain-specific class, it uses a generic storage container (a dictionary). This makes dealing with these task classes cumbersome. We will look at this in the next part.
Summary
I appreciate that this was a larger step than typical in a refactoring cycle, but usually, you are already in a better state when you start. (At least the Clean Architecture is set up by default). So this had to be done in one go. The code was running as it was, but of course, it was slow as it was calling OpenAI and Pinecone. We will deal with this in the following steps by writing “Test Doubles”, classes that look like the real deal but only fake the results from the cache and allow us to test that the code runs.
Next steps:
TestDoubles for OpenAI and PineCone
Move all openai calls to the openai_service class
Move all Pinecone calls to the pinecone_service class
General cleanup (inline, list comprehensions)
Calls to openai look like repeated code. Maybe this can be simplified?
Task class (this will be a really big one, so perhaps it will have its own blog post)
I hope you enjoyed this and subscribe if you are interested in the next parts:
[Edit]
The entire series:
Part 1: Code Review - planning the refactoring and identifying issues
Part 2 (this): Clean Architecture - establishing the general structure
Part 3: Better service classes and test doubles - decouple from external services and replace them with mocks.
Part 4: Preparing to introduce the Task class and first steps
If you would like to see another refactoring, take a look at this one:
https://laszlo.substack.com/p/refactoring-the-titanic
Or, if you would watch a video on Clean Architecture:
https://laszlo.substack.com/p/slides-for-my-talk-at-pydata-london